Neural nets, as defined by the flagship multi-layer perceptron (MLP) model, have their roots from biological research from the 1940’s. In the past half-century, they have made the rounds in research, business, and media. They are among the best tools in terms of automated, self-programming classifiers. But why are none yet known to provide anything close to animal-like brain-based intelligence?
There are two possible camps for explaining why. The first believes a sufficiently large and complex neural net can eventually provide true intelligence. This camp focuses efforts on more complex internal learning rules and larger scale computing to run this neural net. If correct, at current rates of development (e.g. Moore’s Law) we can expect to mirror animal-like brain-based intelligence in a matter of decades. If not, then we would at least have learned useful knowledge about biology and engineering.
The second camp believes there is some unspecified gestalt not quite amenable to the neuron level. A neural net models neurons. Perhaps modeling intelligence with neurons is like modeling an animal with oxygen, carbon, hydrogen, nitrogen, calcium, and phosphorus atoms. Possible, but the task could be much easier and more enlightening on a different scale. If correct, then finding the appropriate scale could allow us to mirror some aspects of animal-like brain-based intelligence very quickly. If not, then we would at least have explored multi-scale analyses of cognition. This article explores the second camp.
To begin, the flagship MLP neural net at the center of the first camp is often termed a slow learning model. It is based on early biological research on the behavior of individual neurons, their ion channels, and their neurotransmitters. Each neuron works together as a team to share and to store memories in a distributed manner. For example, say three neurons work together to store a memory of our grandmother’s face. Those same three neurons also work together to store a memory of Bill Clinton’s face.
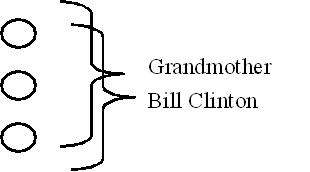
In order to do this, each neuron in the slow learning net adjusts itself and its connections slowly and in a coordinated fashion when learning a face so as not to disturb memories of another face. This process is necessarily slow, but the upside is if the brain takes a heavy blow resulting in the death of one of those three neurons, memories of both grandmother and Bill Clinton are mostly intact if a bit fuzzy. Because of these and other reasons, slow learning neural nets appear more biologically plausible.
In contrast, there is another more obscure form of neural net often termed a fast learning model. It is based on slightly later cognitive research on memory formation and interactions. Fast learning nets use the same architecture and set up as slow learning nets. The key difference is how the neurons interact. In a fast learning net, each neuron works independently to store individual memories. For example, if there were three fast learning neurons, only one stores the entire memory of grandmother’s face. Another stores Bill Clinton’s face.

Since each neuron works independently, there is no need to slow down, wait, and coordinate with any other neurons when learning or recalling. Therefore, each neuron can complete the entire memory imprinting process immediately with “grandmother cells” and “Bill Clinton cells.” The process if fast, but the downside is if the brain takes a hit and loses the grandmother neuron, then memory of grandmother disappears while Bill Clinton is completely safe.
There are several demurrals against this form of neural net. First, if there are three neurons, then there are a maximum of three memories. But no person in history is ever known to have experienced an “out of memory error.” Second, fast learning nets do not explain how similar memories can be associated together. Each memory is independent and unique, but in reality we know grandmother’s face is like grandfather’s face and this reminds us of mom or dad’s face and so on. Third, real neurons exhibit analog activity levels (i.e. any grandmother cell is also active when nowhere near grandmother – albeit at a weaker level.) Unless grandmother is everywhere, this activity is unexplained. Because of this and other reasons, fast learning neural nets do not appear biologically plausible.
But it gets more complicated. Fast learning neural nets operate like abstract probabilistic constructs like radial basis functions, Parzen windows, Bayesian networks, or linear discriminant functions, making them appear even less biologically plausible on the neural scale. This means (A) neuroscience research often skips these forms of models since they may not classify as biological enough to attract neuroscience funding and (B) statistics research often does not consider biological implications for the same reason. The second camp is looking like a tougher path and with fewer members vis-à-vis the first. But let us consider an apples to apples comparison objectively using the same crude 4-point scale from the previous post: simulating the brain on biological, micro, macro, and meta scales.
Fast learning neural nets do not derive from the neuron physiology research from the 1940’s. Instead, they come from cognition research. They also come from empirical clinical research. One Henry Molaison suffered from life threatening seizures and had his medial temporal lobe surgically removed. His seizures stopped, but so too did his ability to form new memories and recall recent memories (i.e. heavy anterograde amnesia and temporally graded retrograde amnesia; antero- means forward or future, retro- means past, a- means not or anti, -mnesia means memory as an mnemonic). In addition, he could develop new skills such as dancing but could not remember learning the new skills.
Starting with this one patient and including several others like him, scientists now understand there are multiple forms of memories that reside in different areas of the brain. For instance, how does one completely remove one recent past memory without harming other memories in the more distance past as in Henry Molaison’s case? This argues for independence in memories, just as with fast learning neural nets. How does one learn new skills without remembering learning them? This argues for a division in the forms of memory, such as procedural memory for mastering skills and episodic memory for storing events. Watching a movie once and talking about it afterwards uses episodic memory. Practicing to be a good actor over years uses procedural memory. Episodic memory resides in the hippocampus located within the medial temporal lobes. Fast learning neural nets simulate hippocampal episodic memory function.
Biologically, the hippocampus is filled with a type of neuron called granule cells. The interesting aspect about hippocampal granule cells is that they experience adult neurogenesis. This means even adult brains are growing new cells everyday, at least within the hippocampus. Tying this fact back to fast learning neural nets yields a rough solution to the “out of memory error.” Perhaps the brain grows new neurons to handle new memories.
To wrap up the total score for fast learning neural nets out of four points: on the biological scale, they can grow and therefore potentially shrink. Memory neurons can easily and automatically achieve the ratios found in nature. This makes one point. On the micro scale, fast learning neural nets completely abstract away neurotransmitter and growth factor details so no points here for basic neuron function. On the macro scale, fast learning neural nets interpreted as modeling episodic memory functions of the hippocampus are clearly linking to the brain regions. However, they still have nothing to do with meta-scale external environmental learning and get zero points there. The total score would be two out of four – still far away from a full score on even a rough measure, but it does open a new perspective forward.
The perspective would be: slow learning neural nets model neurons and their interactions while fast learning neural nets – I would call them “memory nets” when interpreted so – model memories and their interactions on a higher scale than the underlying neurons. Neural net research could better lead to neurochemical treatments through synthesized neurotransmitter compounds and synaptic growth factors. In contrast, memory net research takes the perspective one scale higher and could better lead to explorations of memory function, treatment, augmentation, and emulation. Alzheimer’s Disease, for example, first strikes and destroys the hippocampus and significant life functions as a result.