
One
can describe a face as the “window to the soul.”
In one study by Porter, et al., (2008 -
Is the face the window to the soul? Investigation of the accuracy
of intuitive judgments of the trustworthiness of human faces.)
participants viewed 34 faces drawn from established humanitarians and 34
faces drawn from Most Wanted criminal lists. The participants were able to correctly decide which face
belonged to which group after a short 30-second perusal.
In another
study, participants were able to correctly describe personality traits
simply by looking at portraits – at least of women. Studying a face provides potentially valuation information in
a human society. The first
step in analyzing a face is to identify and track one.
So
how does the brain perform this trick we take for granted?
Newborn infants can pick out and fixate on parents’ faces.
They can even pick out and fixate on face-like icons (e.g.
Dannemiller & Stephens, 1988; Johnson & Morton, 1991), as for
example the below image:

Figure
1.
As
long as there are two blobs where the eyes should be and another blob
where the mouth should be, newborn infants under an hour old can track and
show preference towards a face vs. a non-face.
This underscores the early cognitive capability to isolate,
identify, and track faces.
Taken
together, identifying faces is a core capability for humans and occurs
relatively very early. How
exactly does it work and is it possible to replicate algorithmically?
If it is possible, especially with different approaches, what does
each approach tell us about the brain?
Starting
with neuroscience approaches, the mechanism for visual perception starts
with the vision components – pupil, lens, vitreous humor, fovea, optic
nerve, and lateral geniculate nucleus. It then flows to the neural
processing, specifically the “what stream” through the temporal lobe
and on to the visual cortex V1 in the occipital lobe.
The “what stream” identifies the object under focus and ties in
strongly to long term memory pattern recognition.
It helps to answer, “Is this a face or not?”
To
rapidly touch upon the underlying complexity involved in the various
processing steps in classifying a face, imagine the face again in figure
1. In this simplified
environment, there is a simple face in a lab white (hospital)
fluorescent-lit background. A
human viewing the image quickly, accurately, and intuitively recognizes
the cartoon face. How does
one break down the precise steps, mechanistically?
To
demonstrate the difficulty, suppose the face in figure 1 appears as the
faces in figure 2 (left and right). The
left face image is smaller or more distant and displaced to lower left.
The right face image is elongated, oriented 45 degrees off
vertical, and partially obscured. Humans are not fooled – these are still faces.

Figure
2.
In
a basic statistical approach, one could keep figure 1 as the prototype
face and perform a pixel-by-pixel comparison.
With about 1000 pixels in these sample images, if 300 match, that
makes 30% similarity. Unfortunately, far fewer than 30% of the pixels in either of
the figure 2 faces would match. This
approach would be fooled.
In
a computational dynamic image warping approach, a target image’s pixels
can be recursively warped one-by-one to transform and overlay on a
prototype image. The more
difficult the warping, the less similar is the target image. Figure 3 demonstrates pictorially.
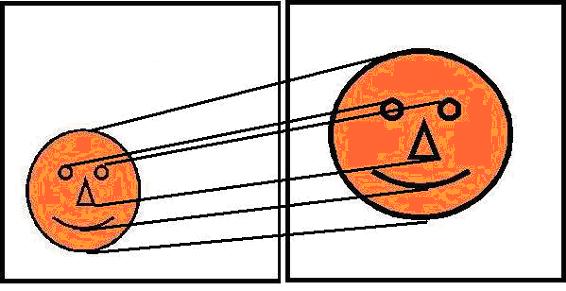
Figure
3.
Basic one-dimensional dynamic
time warping algorithms operate in O(n^2) time – that is, they
require second order exponential time more to complete on complex,
real-life sequences. These
images are two-dimensional, which raises the exponents further.
Add to this the possibility of orientation changes and exponents
rise ever further. This
approach might not be fooled by the location, scale, and orientation
changes, but it implies every infant generates years’ worth of
backlogged images to process every minute.
Other
approaches, e.g. as seen at past Neural
Conferences propose using sliding windows.
Figure 4 demonstrates the approach pictorially.

Figure
4.
In
essence, the prototype image in figure 1 gets rescaled (a simple operation
when scaled down by itself) to say, ¾ size and placed sequentially in
every row and column coordinate in the field. At each coordinate, the
approach performs a pixel-by-pixel comparison of only that corresponding
region. It repeats at
different re-scales as needed. It
repeats at different orientations as needed.
This could take as much or as little processing as desired and
could be as fool-proof or foolish as needed.
The advantage is that this approach can theoretically be done
massively in parallel.
A simple computer vision approach, assuming human-face-only constraint and knowing that human skin tones group around specific mean and standard deviation Red/Blue/Green - 255:255:255 pixel color values easily separates skin-toned pixels from non-skin-toned pixels. Faces in all figures here would be trivial to detect and very fast in O(n) linear time. This would be fast and simple, yet accurate enough to detect a face at all orientations, sizes, and regardless of obscuring. However, it is highly specific to human skin tones in good lighting conditions.
A
similar concept, based on Yacoob
& Davis (1994) analyzes the orientation of any sufficiently oval
or circular face-blob and guesses where the eyes, nose, and mouth should
be within. Given these search areas, it analyzes whether the contrasted
shapes at those locations are of sufficient circularity or curvature to
describe an eye or a nose or a mouth.
These are essentially piece-wise facial “anchors” to detect and
even analyze the face.
Variations
of these general approaches appear in everyday gadgets.
Digital cameras (e.g. Canon) often employ face-tracking software.
Online photo-sharing sites (e.g. PicasaWeb) do the same on static
images to facilitate image descriptions.
One could, if so inclined, experiment with these tools and test how
well they can detect a face given different lighting conditions, with or
without partial obstructions, or with increasingly more horizontal
orientations. Different manufacturers and even different models might use
different approaches, depending on the available computational processing
and product budget. They
generally perform their task reasonably well under conditions typically
expected by the designers.
What
do these applied everyday tools for everyday facial detection tell us
about how an infant can identify and fixate on a face?
Clearly, no amount of rotating the facial orientation relative to
the infant disrupts the face detection.
A half-“Peek-a-boo” likewise would typically fail to trick the
infant. And the infants are
not dealing with any backlog of images. So which of the above approaches or combinations thereof
comes closest to describing how a human – even an infant – performs
this facial detection task?
Which
is the most important factor in any approach: Accuracy?
Precision? Flexibility?
Speed? Inclusion of
brain-like medial, temporal, and occipital lobe structures?
The simple answer is that it depends on the perspective – a
computer scientist might focus on the computational algorithmic complexity
and speed, a product engineer would focus on accuracy to make the product
perform, a business analyst would focus on flexibility of conditions, and
a neuroscientist would focus on including neurological form and function. The complex answer is that these approaches appear to imply
the brain cannot possibly do what the brain apparently does.
Resolving
this contradiction may require not advancements in technology and
techniques, but perhaps advancements and dialogues in perspectives.
What does it mean to be a “window to the soul?”