Where
have all the simple non-linear neural networks gone?
In
1987, Dr. Bart Kosko designed and published the Bidirectional
Associative Memory
(BAM) network.
Referenced in Jeff Hawkins' book, On
Intelligence,
it is one of the most biologically plausible, intricately non-linear, and
on-line adaptive associative memory models.
It can instantly store hi-fidelity patterns and associate them to
another pattern (e.g. This musical score belongs to Mozart; this musical
score belongs to Bach).
It can even store the relationships forwards and backwards (e.g.
Mozart's music sounds like this musical score).
It is highly noise and missing data tolerant (e.g. this musical
fragment sounds like something from Mozart;
"Mzrt" could be Mozart and his music would be thus).
And best of all, the BAM network can run on a simple PC.
From 1987.
Yet
there are relatively few academic references extending such an interesting
and potentially useful model over the past two decades.
And precious little uptake in professional use as far as can be
determined.
For instance, Backpropagation Networks, Adaptive Resonance Theory
Models, Radial Basis Functions, Support Vector Machines, Hidden Markov
Models, and other contemporaries have far more business and professional
use and experimentation.
The vast majority of these alternative models require far more
computing power, yet are limited in their ability to run forward/backward,
require painstaking manual training, and are unstable with respect to
training presentation and paradigm.
The complex and computationally expensive models are embedded in
many academic and professional circles.
But where are the simple ones?
To
be fair, BAM is a heteroassociative model. Its forte is not specialized
for pure classification accuracy as is the case for maximum margin support
vector machines or highly parameterizable Backpropagation models.
A BAM technically has no parameters or tweakable internal settings.
Its strength and focus is on linking or associating multiple disparate
patterns together. It has more in common with Kohonen or Hopfield Networks
than with the conventional prediction models commonly included in computer
science machine
learning or neuroscience modeling
texts. The below figures briefly demonstrate the BAM operations.
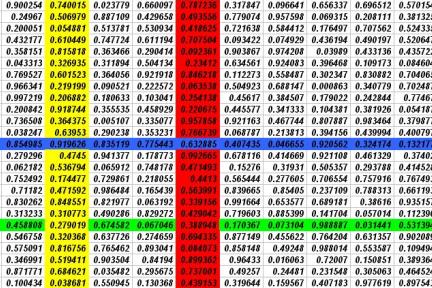
For
simplicity, we wish to encode a 3x3=9 boolean pixel image of the Chinese
number yi (one).
It forms a horizontal bar on the lower 3 pixels like so:

We
can represent these 9 pixels in a (blue) bi-directional single vector,
where –1 represents an empty pixel and +1 represents a filled pixel.
We wish to associate or translate this Chinese number yi to a
(green) 3 feature vector one [-1,-1,1].

Vector
multiply the 9-pixel blue and 3-feature green vectors to arrive at a 9x3
teal matrix.
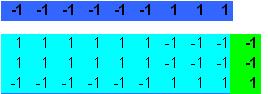
This
teal matrix represents the association between the Chinese yi and the
digitized 1.
We
also wish to translate Chinese er (two) appearing as two horizontal bars
into a digitized two as repeated below.

Add
the two teal matrices and arrive at the core BAM “brain.”
This stores four patterns and two associations in a single 9x3
matrix.
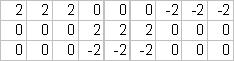
To
extract any of the four patterns, (1) multiply, say, the column vector
side of an association on the BAM “brain” matrix, (2) sum the 9
columns to arrive at a single 9 pixel vector, (3) threshold each pixel
such that values greater than 0 become filled and values less than or
equal to 0 become empty, and (4) arrange the pixels into a 3x3 image.
In this case, entering the digitized two [-1,1,-1] into the BAM
“brain” causes it to reveal the Chinese number er.
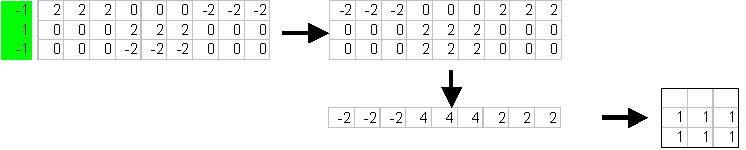
Some
simple experimentation in Excel shows the BAM “brain” to be noise
tolerant.
Computational complexity is O(c); that is, it runs in constant time
regardless of the amount of patterns and association data.
This is a hugely desirable trait.
As a biological model, it is consistent with a 70-year old not
requiring 10x as much time to respond to, “What is your name?” as a
7-year old.
A
BAM is an associative model.
By setting up the association patterns, it can produce predictions
like any machine learning or predictive model.
In this manner, associative models are supersets of predictive or
classification models.
So why are these not used or explored as much as their cousin
classification models?
Potential
explanations why include: (1) BAM models run in constant time, but have a
fuzzy limit on the number of patterns and associations safely stored in a
fixed BAM “brain.”
This limit is generally equal to the lesser of the two vector
sizes.
However, this limit can be exceeded before this point if the
patterns are sufficiently similar to produce crosstalk.
(2) The output when it exceeds this fuzzy limit is unpredictable.
It may produce novel output patterns never before stored.
If it is set as a 2-class classifier, a BAM might conceivably
produce a third option with no warning.
On
the other hand, mixing up similar patterns and associations is consistent
with real people mixing up similar facts in real life.
For example, a person may view a face and remark that they have
“their mother’s eyes” but “their father’s chin.”
Going further, this mixing and production of novel patterns might
offer potential avenues for exploring creativity – how does an artist
create various art forms such as classical symphonies or impressionist
art?
These are not constrained 2-alternative forced choice
classification tasks.
In
any case, BAM models and derivatives are intriguing, yet apparently hidden
gems of models well deserving of further exploration.