Less is more, as the saying goes. While in theory having more information should enable better decision making, in practice this is not always so. The distinction starts with the vocabulary and what it implies.
Computer scientists might call them input attributes. Signal processing engineers might call them features. Mathematicians might call them vector dimensions. The more there are of these attributes, features, or dimensions available for input into a decision system means the higher the complexity. Increased complexity provides two main benefits: (1) It provides more potential material for processing and refining, like large rough diamonds that provide better probabilities for producing large carat refined jewels; and (2) It often sells better since the complexity is intimidating to non-specialists who might be better convinced to part with tax and research funding.
But in neuroscience, the analogs are called sensory stimuli. These are the neurons that look and operate essentially like any other neuron, but are tied to visual receptors (rods and cones), audio receptors (pitch sensitive inner hair cells), touch receptors, or other sense organs. These have the sole responsibility of carrying all external environmental stimuli to the brain. Having a sensory neuron actively “listening” to the external environment lets the brain know where the body is and what it is doing. Having a sensory neuron “disabled” or otherwise ignored isolates the brain a bit more from the environment. More active sensory neurons available should mean a more alert and active person, in theory.
In practice, having all the sensory neurons activated simultaneously tends to cause sensory overload. For example, a stun grenade or “flash bang” used by police forces in less-than-lethal situations can temporarily disable the suspects by precisely this mechanism. The extreme “flash” of light and the extremely loud “bang” of sound causes even the most hardened suspect to reel in confusion. If it were even remotely true that humans use only a portion of their available brain cells in a given time frame (e.g. the 10% myth), this should provide some evidence that fully stimulating all of them all the time would not be a good idea. Severe brain damage may ensue.
Therefore, a mechanism to control the level of sensory stimuli is a natural core function in neuroscience. The research direction is called selective attention (e.g. Kane & Engle, 2002). Most highly correlated with the prefrontal cortex, selective attention allows top-down and bottom-up forms of restricting sensory neuron access to the brain by the simple expedient of ignoring non-critical or non-salient stimuli. If a typical adult reading this is sitting down, there is the equivalent of about 100-150 pounds standing on their buttocks right this moment. There is also about 5 pounds of clothes weighing on the shoulders, neck, and hips. This is basic physics e.g. Newton’s Laws of Motion about action and reaction. Yet most if not all would be hard pressed to notice such sensory stimuli, even when pointed out.
Machine learning and data mining analogs to selective attention are dimensionality reduction, feature selection, or attribute selection. In a classic text on Data Mining (e.g. Witten & Frank, 2005) there are about 15 pages devoted to attribute selection in a 500-page book, so this is hardly a core interest. The basic approaches to feature selection involve additive or subtractive stepwise, stochastic evolution, and orthogonal latent variable finding.
Additive stepwise involves beginning with no features, then incrementally adding them one by one while continually tracking if the end result is improving. Additive subtractive goes the opposite direction by starting with all features and incrementally removing them. Stochastic evolution borrows from genetic algorithms to swarm a random population of feature subsets. The individuals in the population with the subsets producing the best end results are retained and combined to create new population swarms. Orthogonal latent variable finding is one of the most popular because (1) it is powerful and yields results and (2) it is complex. The prime example is Principal Component Analysis (PCA).
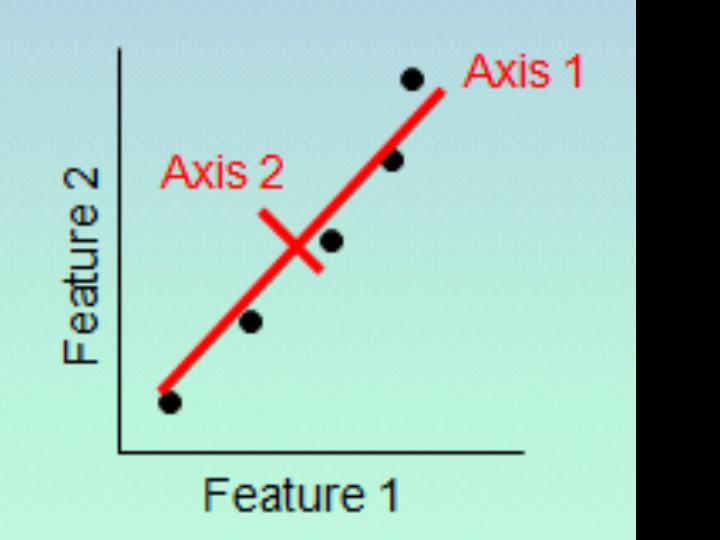
Figure 1. Sample Principal Component Analysis projection of two features
(Feature 1 and Feature 2) onto latent variable axes (Axis 1 and Axis 2).
The PCA concept is as follows: If we had five data points projected on a plane over two features, we might see an image like Figure 1 (black). If we wished to reduce these features down to one, PCA allows the data to be re-cast in new latent dimensions corresponding to the orthogonal eigenvalues in Figure 1 (red). Selecting the latent dimension with the highest eigenvalue (i.e. the longest red line, Axis 1) conserves the most information while retaining only one latent dimension.
Again, the machine learning and data mining concept is to retain the most information for the best results. This is data compression, like a Zip-file. This contrasts with the concept in neuroscience. A related, but much different algorithmic approach from a neuroscience perspective can be found here.
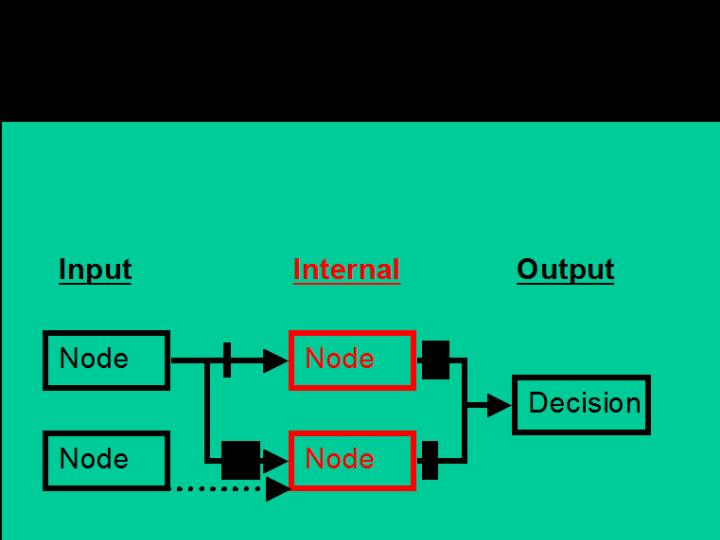
Figure 2. The conceptual CARTMAP approach.
Input nodes (sensory neuron) feed into general purpose internal
nodes (red, analogously corresponding to the red axes in Figure 1).
Non-interesting input nodes are not compressed and retained but
essentially ignored (e.g. dashed line).
The CARTMAP (Clustered ARTMAP) principally uses off-the-shelf clustering to combine similar sensory stimuli before presenting the reduced set to an adaptive learning system. The core concept is not on retaining the most information in the least amount of space as in data compression. Nor is the core concept to produce the best end result no matter the code or algorithmic tweaking and extension cost. The demonstration used off-the-shelf materials in a different framework arrangement. The core concept is about ignoring similar features completely. A physiological demonstration:
· Get two pins. (pencil tips will work also, but it gets more difficult)
· Form small calipers and press gently on the back of the hand.
·
Make the calipers smaller until the sensation on the hand
appears as if there were only 1 pin.
·
Works best with a friend with the eyes closed.
We can call this skin touch receptor resolution. We can call this a touch sensory On/Off Center/Surround neuron configuration. We can call this clustering. The concept is that our skin is ignoring the second pin by effectively completely discarding the sensation. There is no mechanism for retrieving the original features. There is no de-compression or un-Zipping. The sensory stimulus is effectively never there.
CARTMAP is similar to PCA in some ways, but profoundly different in others. Both nominally reduce the input set of features or stimuli. Both produce minimally correlated (i.e. orthogonal) resulting features. Both may produce improved end results. But PCA focuses on feature reduction while attempting to retain information for better or at least less-worse end result accuracy. CARTMAP focuses on simply ignoring the non-salient stimuli. This is because even though CARTMAP can be used as an effective stand-alone tool, it was designed for much more. It was a model to provide a partial explanation of how a selective attention mechanism might operate in a person that in turn makes the person who they are.