
Is Machine Learning Really a Machine Learning?
Machine
Learning is a hot topic for study and applications. It is a subfield
of Computer Science focused on generalizing with known data for
predictions with unknown data. It is an enabling technology for Big
Data. A modern spam filter, for example, more often than not uses
machine learning algorithms to predict whether incoming email messages are
spam or not spam. A modern hospital diagnosis tool to assist health
care professionals makes use of machine learning and big data mining.
It
follows to ask whether machine learning is on track to help “solve”
the Artificial Intelligence problem – can computers ever become
“smart” like a person? It follows to ask, “Today, spam;
Tomorrow, the world?” Is machine learning about a machine that
learns? And if learning efficiently is what makes us human, then a
machine that learns sufficiently efficiently should be like a human for
all intents and purposes. Let us explore this syllogism.
Phase
1. The Expert System.
In
the 1970’s, expert systems proliferated in computer science. An
expert system is a set of rules or facts combined with a logic module that
essentially queries the rules and fills in gaps to make a conclusion.
In a health care diagnosis system, it might work like this:
Input: Fever,
stomachache, headache.
Output: Flu.
The
expert system contains a list of input symptoms tied to outputs such as,
“IF fever -> THEN flu…” The system receives inputs,
“Fever; Stomachache; Headache,” runs them on this list of input
symptoms in the database, tallies up the outputs, and responds, “Flu.”
Maintaining the list of symptoms requires, say, a database administrator
performing overnight batch updates. Maintaining the logic and query
system requires a programmer to change the code in the development area,
try it out with a select group of end-users in the test area, and finally
release the code patch to production in an overnight batch update.
This setup might be marketed to the world with slogans like, “80% of
doctors and nurses agree with the AutoDoc Health Care Expert System…”
Except
that might not be what makes a healthcare professional a healthcare
professional. This makes an internet self-diagnosis board of limited
utility that makes everyone think they have the flu.
Phase
2. The Big Data Expert System.
Today,
there is a profusion of online data available. New articles are
being posted and published online at ever increasing rates. A
healthcare professional has about 15 minutes allotted per patient. This
includes preparation time, research time, and interview time. There
is a literal ton of background features and data available that must be
taken into account before making a diagnosis. Missing a critical
piece of information when making a diagnosis can lead to fairly severe
malpractice charges. A machine learning system might work like this:
Input: Fever,
Stomachache, Headache.
CrossCheck: Age,
Weight, Height, Past Travels, Patient Recent History, Patient Long Term
History, Patient Immunization Records, Patient Billing Records, Patient
Dietary Records, Patient Skin Tone, Patient Gender, Patient Psychological
Profile,…
Output: Flu,
80% probability. Spotted Fever, 25% probability.
The
procedure is similar to the basic expert system, with emphasis on scanning
and extracting more information from among tons of available online data.
This online data mining allows for double-checking against more rules.
The primary enabling technology is a more efficient logic module on bigger
and faster processors. For example, a more efficient means of
quickly searching a patient’s text history during a 15-minute visit
might make use of text indexing. Instead of linearly searching tons
of patient history text notes during the each visit for the word, “flu
shot,” the big data expert system might include something like an Aho-Corasick or
derivative.
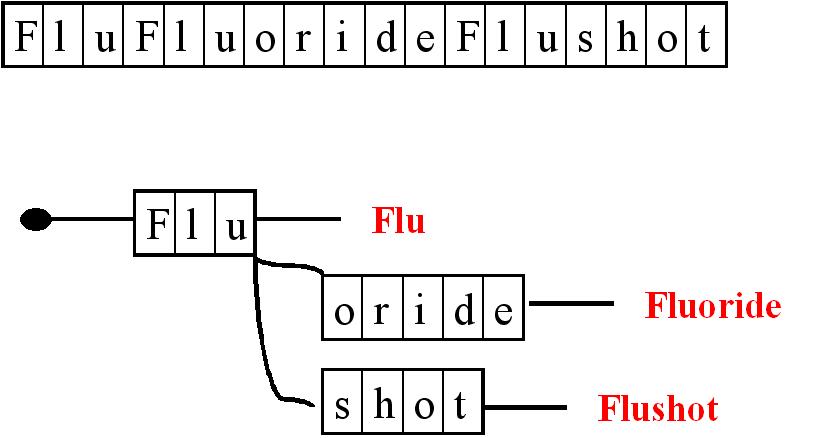
In
this simple example, a list of terms in the text (top) gets transformed
and indexed using a one-pass word filter (bottom). Searching the
original text, “fluflourideflushot…” for each word individually ad
hoc takes time. Searching the already processed text for the
presence of the word, “flushot,” is much faster and easier. Each
patient document can be indexed and preprocessed in an overnight batch to
be ready for a very rapid term search during a patient visit. This
makes it possible to quickly perform a massive, big data crosscheck on any
desired patient attribute in a massive, feature-rich database. This
setup might be marketed to the world with slogans like, “Experts agree
that the thoroughness of the Systematic AutoDeepDoctor (SADD) improves
healthcare practice by 90%…”
Except
that might not be what makes a healthcare professional a healthcare
professional either. This makes a highly linked internet
self-diagnosis board of limited utility that makes everyone think they might
have cancer and spotted fever instead of the flu.
Phase
3. The Professional Guide
Computers
do what they are programmed to do. Massive amounts of data are
available for computers to do something with them. Together, they
produce big data solutions. But a healthcare professional is first
and foremost a guide. They do not only heal the sick; they help us
to live. A doctor
is a teacher. A professional guide might work like this:
Input: Fever,
Stomachache, Headache.
InitialResponse: There
is a flu going around. How long have you had these? How is
everyone else in your household? Take plenty of fluids… Get
rest… wait X days and let me know if the symptoms remain… I am here
for you…
FollowUpResponse: Still
have persistent fever and stomachache... Let us together check for X,
confirm or deny Y, try out solution Z...
The
professional guide empathizes with the patient, gets in the patient’s
metaphorical shoes, sketches out a course of action, and reassures the
patient to build trust, confidence, and rapport. Along the way, they
qualitatively crosscheck both within patient history and across other
patients.
This
presents a stark contrast with the machine learning approaches.
Schematically, a machine learning system takes in historical data, stores
it in such a way as to maximize generalization, and then extrapolates from
this stored data to make predictions.
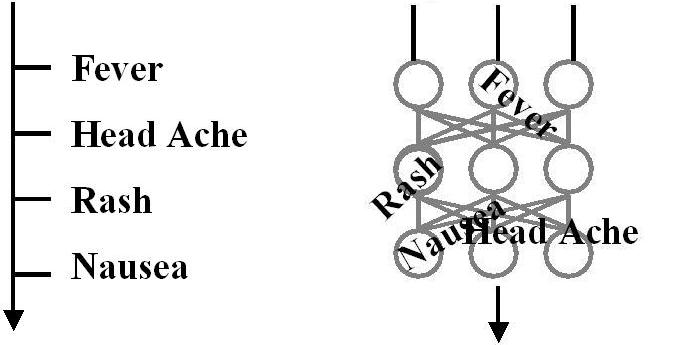
{kind=link}
{kind=link}
On
the left is a segregated machine learning data structure. A
segregated data structure works like a database of rules. It forms
the basis for databases, K-nn, Radial Basis Functions, Bayesian belief
networks, decision trees, linear discrimination analyses, and types of
support vector machines using appropriate kernels. An Aho-Corasick
tree works using such a data structure. The theory and practice
behind these forms is clearly understood and mapped.
On
the right is a distributed machine learning structure. A distributed
data structure is modeled (very) loosely on the biological brain. It
forms the basis for types of support vector machines using specialized
kernels and for artificial neural networks, machine learning-style.
All rules are shared and combined and re-combined in the network to
exhibit damage resistance (any lost node does not completely remove any
crucial rule), fixed storage size (there is never any need to expand the
physical storage), and rule re-combinations. The rule re-combination
attracts the center of attention because it allows new rules to
theoretically be formed in unknown, unknowable, and unexpected manners.
It forms a high-risk, high-reward, “Hail Mary” approach to strive
towards artificial intelligence.
In
all forms, the goal of the machine learning is to copy and store the known
data into the selected data structure. In a segregated structure,
linking a fever to a flu involves simply writing, “IF fever -> THEN
flu.” In a distributed structure, it gets more complex by weaving
network weights such that “Input Node: Fever -> increases energy
output for Output Node: Flu AND decreases energy output for all other
Output Nodes.”
The
key aspect here is that the machine learning algorithms’ goal is
essentially to STORE data to a specific data structure. A medical
textbook stores rules. It can store it ordered by an index or it can
store it ordered by a stream-of-consciousness narrative, but the job is to
store. A healthcare professional makes decisions and treats. A
medical textbook is no more a physician replacement than is any current
instance of a machine-learning algorithm. A half-written textbook is
not in training or learning. A half-written rule base is not in
training or learning. A half-stored rule base regardless of data
structure is not in training or learning. Perhaps “Machine
Learning” should be more aptly renamed “Machine Storage.”
Getting
a computer to Phase 3 then might not be related to the underlying data
structure. An artificial neural network, machine learning-style does
not provide significantly more ability than an Aho-Corasick type look-up
approach. Clearly, whatever the reason our biological brains use a
connectionist data structure, it is not simply for the structure that
makes a person smart like a person. The structure type may be
necessary, but alone is not sufficient.
As
Phase 3 may point out, a human healthcare professional guide is not about
storing knowledge. While it is important, that is not the defining
characteristic. If learning is part of being human, then it is not
simply learning facts and figures. It might be learning about
someone else. A professional guide learns about the patient and
gains their trust and rapport. A professional guide grows towards
the patient and allows the patient to grow towards the guide.
Perhaps
on this note, a biologically modeled, distributed, connectionist-like data
structure is not sufficient, but necessary. It may be an enabling
basis in ways that a segregated structure is not. By simple
definition, the connections in a distributed, connectionist structure can
grow. By simple definition, this is drastically different than the
artificial neural network, machine-learning style. The connections
must be allowed to grow within layers, rather than just between layers as
in the above figure on the right. And the connections should allow
two-way antidromic responses. In this way, learning is not just learning;
learning is growing. When there is a “Machine Growing”
algorithm, then we might at last be on the path.