
Question:
There is a list or data table in the following format:
[Name,
Items Bought]
with
the following sample snippet:
[Jim,
15]
[Peter,
25]
[Samantha,
23]
[Jim,
43]
[Peter,
12]
[Jessica,
12]
Efficiently
put together a report totaling the items by unique name.
Solution
1: Quickly
use a pre-built SQL function since SQL is specialized for exactly this
question. The SQL code would
be this:
SELECT
DISTINCTROW Name, Sum(Items) AS Total Items
FROM
Table
GROUP
BY Name
This
should take all of 30 seconds to set up.
Solution
2: Quickly
use another pre-built SQL-like function in any supporting programming
language of choice, say a dictionary in Python or an associative array in
Java. The code would be like
this:
report=collections.defaultdict(int)
For
name, count in table:
report[name]+=count
This
should take all of 45 seconds to set up.
Simple.
Effective. Fast.
Anyone at all involved in this process – from report requesting
to report generation – should know the basic idea within their first
year working. It is a
transformation and filtering of the data into… more data.
Analogy:
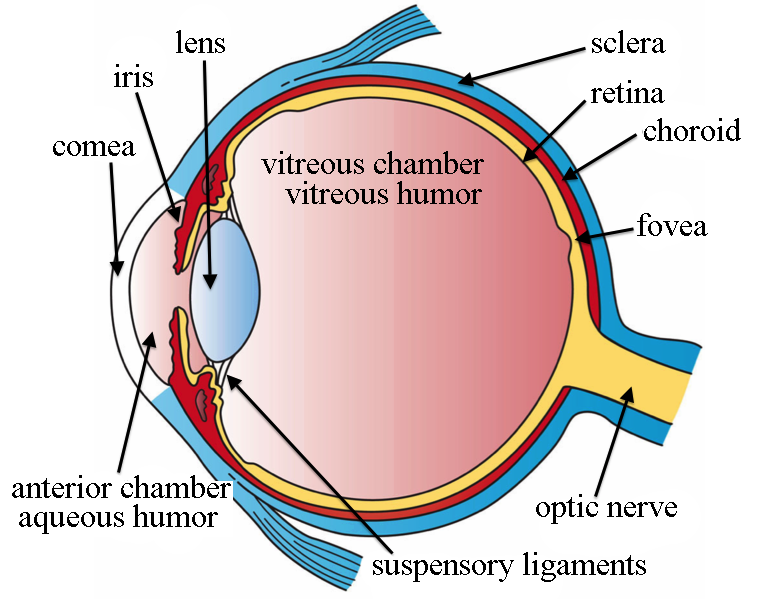
humans visually process the scene in front of them.
Light reflected from the environment enters the eye, through the
lens, through the vitreous humor, and onto the retina.
Then
the light radiation stimulates specific retinal cells (e.g. rods, cones)
and their associated optic neurons (e.g. horizontal cells, amacrine cells)
that discharge onto the lateral
geniculate nucleus (e.g. parvocellular
– small, colored, steady detectors; and magnocellular – large, motion,
fast detectors) before projection to the visual cortex at the back of our
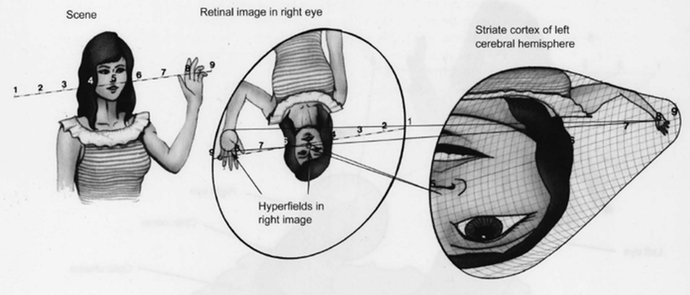
heads. At the end of this
process, the image (i.e. as projected to the striate cortex in V1) is a
roughly upside down version of the outside environment twisted and
magnified as if on a convoluted mirror.
It
is a transformation and filtering of the data into… more data.
There
are thus two issues with this question and the answers.
1.
Is the set up investment worth the expected use?
The
trained, yet unseasoned analyst will know about the built-in shortcuts and
functions in SQL, Java, Python, visual cortex, and the like.
Using these shortcuts is a textbook exercise taking about 30-45
seconds to setup.
The
really trained analyst will know how to recreate these functions from
scratch – especially since not all languages will have these pre-built
functions. Creating the function requires extensive indexing (e.g.
Aho-Corasick dictionary matching complete with index links) which may take
a one-time setup investment of days before each individual 30-45 second
setup. The alternative is to
use a nested pass to meticulously compare, group, count, and sort the
names and items bought. There
is no setup investment, but each individual run may take hours.
The
seasoned professional needs to ask and project how many times this
function may be used BEFORE being anchored and biased towards using it
just because it exists. This
is a variation on the sunk cost / moral hazard concepts – just because
it exists and cost so much investment does not mean it is necessarily
appropriate to use. The
pre-built function exists to do what it was built to do.
Using it as a choice forces the analyst to frame the question in
terms of multiple choices on the terms of the pre-built function.
Just because we spent so much to get a car does not mean we should
drive 50 meters to the grocery store.
This is a serious bias.
2.
The ultimate and ultimately more important question is:
What
is the point of the data reporting? In
other words, what was the original question before it got to the one
listed at the beginning? Report
writing has hidden (latent) variables.
Real life has hidden questions.
Working
backwards, Professor Kahneman in Thinking
Fast or Slow would say the common question listed at the beginning is
the easier-to-answer heuristic question in response to a hidden, more
difficult target question. In
more comical terms, Scott Adams in Dilbert
often has the joke along the lines that people’s questions are those
they are best at answering – such that the marketing executive wants
more marketing research, the engineer wants to build an engineering model,
and the hot-tempered impatient folks want to “kick some hiney.”
They all ignore the original question and reframe it in terms that
they each individually know.
The
original question – in one form or another a key one for all businesses
– is what do the customers want and how do we give it to them?
The original question – in one form or another a key one for all
living animals – is how do I fit and adapt to this environment?
Focusing on the reporting scale might serve as a distraction on the
key scale.
Eyeballs,
surprising enough to us humans biased towards making everything visual,
are technically
optional for seeing.
One
final note to belabor the connection between data structures and their
intended use and nomenclature: Java
calls the SQL-friendly dictionaries as “associative arrays” as in it
forms associations much like associative learning.
This is a misnomer of an egregious order.
Here is why:
An
array data structure is a numeric-indexed set of data entries.
data[1]
= “a”
data[2]
= “b”
data[3]
= ”c”
To
access the 3rd data entry, we do not need to check the first,
then second, then third data entry. We
simply access data record [3]. Think
of a physical library. We use
the Dewey Decimal System to locate a text by its numeric index code.
An
associative array data structure is a non-numeric-indexed set of data
entries.
data[“gray”]
= “a”
data[“blue”]
= ”b”
data[“pink”]
= ”c”
To access what letter “associates” with “blue”, we simply access data record [“blue”]. This is like saying the data array “associates” the letter “c” with the number 3. Technically this is true, but is seriously misleading.
Human associative memory refers to more of a self-organizing, top-down selective attention-mediated bottom-up feature clustering coincident detector. Clearly, this is for neither here nor now. But suffice to say, it is the opinion of this scientist that the terms “associative array” and “machine learning” be understood as differing from neuro-biological association and learning. Perhaps at least internally, they would be better served as “non-numeric-indexed data” and “machine storage.” This may help alleviate the inherent bias to misuse this pre-built functionality for which they were intended.