
The PseudoScience of Bad Data Science
Let
us bake cupcakes for a moment. Better
yet, let us start a cupcake bakery shop.
There are two basic approaches.
1.
We have been eating cupcakes since time immemorial.
Our earliest memories are of eating cupcakes of the kind Grandma
Mae used to bake. We remember
sitting in her kitchen, watching her patiently sift flour, sugar, cream,
butter, and eggs all in her sure, loving, timeless, caring way.
She would slowly and gently layer the ingredients, feeling,
touching, and balancing them the whole time.
Each cupcake was a product of a lifetime of love, patience, and
care. The final product was something her customers would travel
for miles to taste. Each
cupcake was a bite of happiness, a return to childhood.
Each bite was a morale boost, re-energizing and re-charging each
customer in ways far more important than the mere caloric.
And because of this, Grandma Mae was happy to wake each morning at
4:30 to prepare batches of cupcakes for her customers. Nay, not her customers, but her guests. Nay, not even that but her family.
The
business challenge is scaling up. When
Grandma Mae retires or needs to expand, how can we find others who can
carry on the cupcake shop? How
can we train those willing to bake happiness in a cup?
How can we pass her skills and talents on through time (next
generations) and space (expansion into new shops)?
How can we replicate that which is unique?
How can we replace the irreplaceable?
This is not an easy task.
2.
We see cupcake shops and notice they are profitable and thriving.
Federal Cupcakes. Commonwealth
Cakes. Sweet Bakery. Cupcakes on Fifth. Crumbs.
So we want in on the cupcake business.
We
get funding from venture capital. The
founders become Chief Executives. We
spend $$$ on getting the location and finding the perfect name.
Thumbs. Then we use
leftovers to hire the best chefs and talent.
We put the talent and staff through the most vigorous hiring tests
to ensure they can run the equipment.
We can’t wait three days turnaround for each cupcake test.
We get the process down with toasters and high-speed fryers to 5
minutes. With this winning
technology, we can generate thousands of different cupcakes for taste
testing. Each cupcake is a
mini thumb sized cake. Thumbs.
Test
time. We database the living
daylights out of the cupcake sample polls.
We find that people actually like one of the cupcake flavors.
We run correlation analyses to tease apart this cupcake from the
others. Our conclusion: it is an organic wheat flour harvested on the
third evening before the fall equinox while under a howling wolf and after
the Washington
Redskins won their final home game in the football season.
Since
the recipe was created on the capital- intensive technology, there is no
weepingly challenging task of scaling up or translation into a
capital-intensive technology. The business challenge is getting the secret recipe that
works. But we can use the
capital-intensive technology to do that too.
We can put the proverbial cart before the horse.
Which
cupcake bakery should we work for? Which
one should we start or fund? The
first is dogged by the age-old problem in business: once we have success,
how do we do the much harder work to scale it?
The second is dogged by the promise of technology: once we have
scale, how do we use it to do the much harder work to get success?
Hold
on a second – how can it be that scaling the success is harder than
getting it, yet finding success is harder than scaling it?
They can’t both be correct!
If the first is true, then getting the harder scaling part down
first should mean we are almost done.
We have the Chief Executives, the fancy location, and the talented
high-speed, low-latency cupcake chefs.
All we need to do is turn the production scaling around and point
it at the recipe search.
Except
that in this case, we really do not have any Chief Executives.
We have a bunch of people with fancy titles who de facto abdicated
the responsibility over to the talented high-speed, low-latency cupcake
chefs. The chefs can take any recipe and turn out a batch of
cupcakes in 5 minutes. But
they do not have any recipe. That
was the job of the business side – the Chief Executives.
There is the shop and the fryers and the toasters and the
infrastructure. But there is
no cupcake. There is no
business model. We do not
actually know what we want to bake. We
have not communicated to the talented chefs any direction other than
“Make me a successful cupcake,” because we do not know any more.
Might as well ask them to “Make me a successful business.” Catering to the polls, the chefs have a high probability of
making spurious cupcakes that sell sporadically and cannot be fixed since
no know really knows what it is. The
cupcakes make no sense. But
they were made perfectly and fast.
Now
let us not bake cupcakes in a bakery shop.
Let us run an advertisement and marketing firm.
Let us sell news. Let
us sell financial instruments. Let
us sell car insurance based on mobile phone activity.
Let us stop crime. But
instead of hiring talented chefs, we hire a bunch of talented high-speed,
low-latency SQL report writers or Support Vector Machine operators or
Principal Component Analysis experts to find us the way through data
mining and data science. We
shall put the pressure and responsibility on them to “Make us a
successful business model” by “Telling a story with the data.”
And
we wonder why the product works sporadically and is extraordinarily
difficult to modify or adjust or fix.
The Washington Redskins Rule fallacy bases a US presidential
election prediction solely on the outcome of the Redskins’ home game
immediately prior to the election. The
rule correctly predicted the presidential winner 95% of the time.
This puts the Redskins predictive feature at the top of any data
science analysis. There are no known data science analyses that can filter this
predictive feature “ingredient” out of the final product. Except that
it makes no sense. Think
about it for a moment. How
could 11 players decide the fate of the US presidential election and
change the world?
The
answer is prosaic and simple: they don’t.
How well does the Baltimore Ravens’ final home game predict the
election? Second to last home
game? Third to last away
game? How about the New
England Patriots first home game? Combination
of third home game after the first winter storm but before the winter
solstice? Plotting these game
rules by their scores would yield something like this:
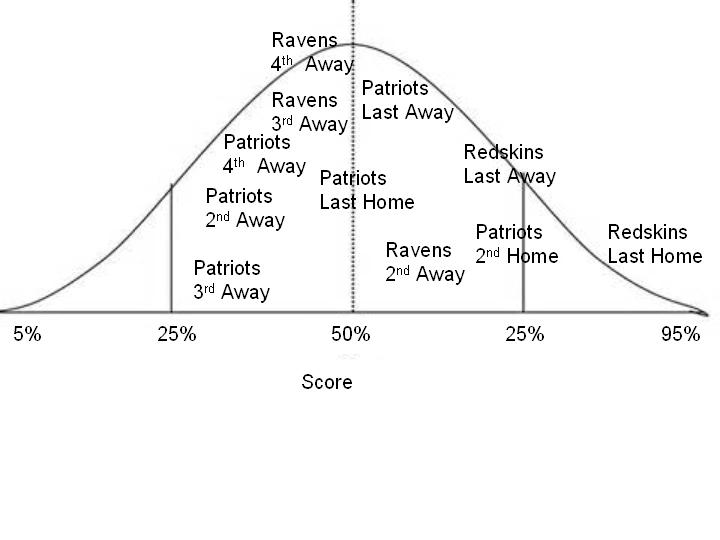
With
enough attempts, anyone can win the lottery multiple times.
With enough people, someone is going to win the lottery multiple
times.
“Scientifically”
testing billions of combinations of feature ingredients is not actually
scientific or science at all if there is no underlying theory.
“Scientifically” sifting through Petabytes of data is not
really scientific or science – regardless of how quickly we can do so.
Any four-year old watching PBS Kids’ Professor Wiseman knows why.
It is more basic than basic science 101.
The
first step in science is to frame a hypothesis/question.
The next step is to decide what kinds of observations to collect to
confirm or deny that hypothesis. If
the observations do not make conclusive sense one way or another, reframe
the hypothesis/question. A
real scientist never starts with a full mass of undisciplined collected
data, no matter how many sexy Petabytes it takes over how many years.
That data is useless if it were not collected to test a hypothesis
or answer a well-framed question. Basing
any research on pre-collected data merely biases the question towards the
data to answer what can be done with that data.
In economic-speak, this is a sunk cost.
In finance-speak, this is throwing good money after bad.
The
mass of stored data is so seductive because it is packaged in a fancy
technology that the uninitiated do not understand.
It is the fancy emperor’s clothes where everyone is afraid to
challenge it and thereby take the risk of looking uninformed and
uninitiated. So let us end
first by inoculating ourselves against this seduction of big data on
people and to clearly state that the emperor is NC-17 rated. Regarding the Petabytes of stored personal online use data,
ask ourselves how many Petabytes of data do we store everyday with our
eyes and ears noticing customers? Would
they be measured in Petabytes or Zettabytes?
Has anyone ever tried to even answer what Petabytes of stored data
means in relation to what we do everyday with our own eyes, ears, hands,
and speech? Do Petabytes of
stored data become less impressive after such a comparison? In all the
rush with technology, we seem to have forgotten the people at the center
of the people data the technology was supposed to help us for.
Second,
let us not focus on using technology to find the successful business
model. Instead let us focus
on using technology to scale it, as in the first scenario.
The age-old hard business challenge of scaling success when we have
it is age-old for a reason. Finding
success is being human. Scaling
it is to understand being human. Rather
than forcing the human to operate on terms of technological scaling
machines, perhaps we can force the technological scaling machine to
operate on terms of humans.
And
finally, the answer to how to detect the fallacy in the Washington
Redskins Rule: or how to detect a likely fake association from a likely
real one if someone really needed to go down this path.
If the Washington Redskins team performance really does somehow
predict the presidential election results, there should be consistency
either temporally or spatially or both. That is, in 1940-1960, the Washington Redskins team
performance should be 66% accurate. Then
in 1960-1980 is should be 83% accurate, with the 1980-2000 showing 95%
accuracy. Or the nearby
Seattle Seahawks would have 80% accuracy while the farther away San
Francisco 49ers would have 60% accuracy.
If adjacent periods of time or space had similar results, then the
results would be intriguing - but not conclusive!
Otherwise, the inconsistency in the random pattern provides
evidence of it being… random.