There is dark, dirty secret at the heart of Artificial Intelligence (AI). In a recent article from MIT (Technoloy Review, 2017), AI is a more becoming more common and now guides Nvidia's program driven car as well as integrating with finance, banking, medicine, and even law. They state the secret as AI being too complex to understand and nobody, even the programmers, can explain why it does as it does.
Having some expertise with this subject, we can confidently state: not quite accurate.
True, there are two major branches in AI: scripted code vs machine learning.
Scripted code is an instruction set of logical rules. (e.g. If green light, then accelerate to 15 mph.) This is theoretically understandable with clear reasoning - simply find which rule triggers the behavior. In practice, scripted code can get extremely complex and convoluted (i.e. "spaghetti code") as more and more computer science programmers add more and more rules. Getting highly trained computer science programmers to clean this growing set of rules can get very expensive and time consuming.
Machine learning gets the computer to generate a set of logical rules. It generates this based on how it stores a series of labeled examples. The algorithm of choice stores and compresses the set of examples into clusters. (e.g. in these past 5 cases, the driver accelerated to 15 mph. In those 11 cases, the driver stopped.) This is theoretically inscrutable, but in practice it is fairly easy to see the clusters in a report. And all we need are a handful of data science programmers to enter the data. The downside is that most models are not that great vs. scripted code under known, circumscribed problems.
One of the machine learning approaches attempts to borrow - very loosely - from biology. Since biological neurons fit into networks, a machine learning Deep Learning (DL) neural network sounds like a biologically inspired algorithm. The short history is that DL was popular in the 1960s, then faded out before coming back in the 1980s, before it faded out and is coming back to main stream in the 2010s. DL is and has always been an inscrutable. Not because machine learning necessarily has to be an inscrutable "black box." Not because biology is an inscrutable "black box." Not because DL is so much more complex or hard. Rather, DL is an inscrutable black box by design - through the purposeful use of internal, uncontrolled layers.
To continue, a brief review of Deep Learning is in order. In 1950s, neuroscientists showed the structure of neural learning in the common squid (it was inexpensive, visible to the naked eye, and PETA did not care about uncooked calamari). In the 1960s, the Perceptron (i.e. let's call it Learning, version 1) translated this learning into a regression-like algorithm. Ironically, it was MIT (Minsky and Papert) that stopped this Deep Learning path in favor of MIT's specialty with scripted code AI. Essentially, the folks at MIT correctly pointed out the Deep Learning path could not accurately store example-driven rules to do what 2 lines of code could do. In the 1980s, Deep Learning (i.e. version 2) was able to perform those 2 lines of code by stacking additional regressions in multiple, deeper layers and run over thousands of repetitions. Now in the 2010s, Deep Deep Learning (i.e. version 2.1) stacks ever more layers of regression for flexibility. But with each stacked layer, it introduces more uncontrolled layers.
To continue, a brief overview of regression and stacked layers. Regression models fit inputs to outputs with a self-driven set of coefficients, or weights. Think Algebra, where the line equation is given by
Y=mX+b
Where (X,Y) are coordinates establishing a line.
m is the slope A.K.A. the coefficient A.K.A. the weight
b is some bias A.K.A. the vertical axis intercept
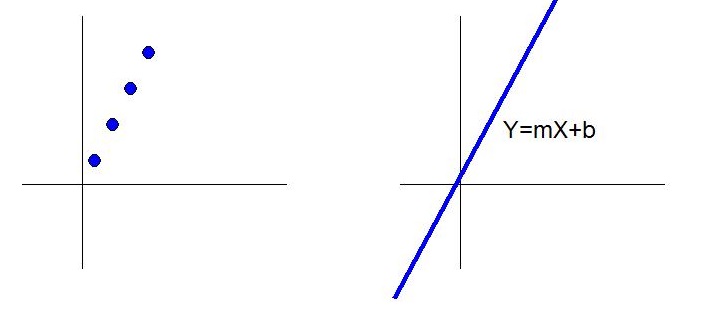
Figure 1.
The regression equation describes a line. This line describes and can replace a series of points with a compressed equation. e.g. (1,2.5) (2,4.5) (3,6.5) and (4,8.5) are 4 points. But we can express them all with one single equation:
Y=2X+0.5
See Figure 1. This equation compresses and stores the 4 points. It can store 400 or 4 million points with a single equation. The input is X. The output is Y. Using the solved equation, when given any X, we can figure out the Y. Solving the equation for unknown m and b when given (X,Y) is "training" the regression. The operator controls (X,Y) and lets the regression solver algorithm find the m and b values on its own. This is a single regression. See Figure 2, top.
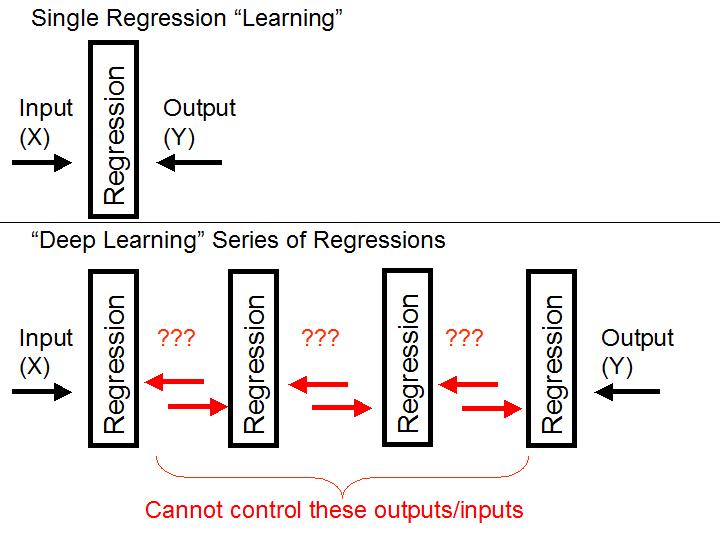
Figure 2.
This changes if there are multiple stacks of regressions. With each additional stacked layer, there is another set of between-layer outputs and inputs. Each stacked regression layer still solves the m and b as normal -- no issue there. Each layer's output becomes the next layer's inputs -- no issue there. But the operator only explicitly declares the overall first input and the last output. The Deep Learning (1980s) approach lets each between-layer outputs and inputs drift. This drifting - often stochastically determined - is the key to generating the novel code that leads from X to Y. See Figure 2, bottom.
These drifting between-layer outputs and inputs are what causes the inscrutable black box effect. They are inscrutable both because they are based on random initial biases and because these drifting between-layer interactions have no explicit purpose other than to essentially make a series of "blind guesses" that hopefully drag into a correct end result (X,Y) as declared by the operator. That's the problem with randomness - it provides no explanatory power. That's the problem with blind guesses. The guesser has no idea why. It's like having 1000 monkeys randomly typing until they get Shakespeare with a juice reward at the end. But none of the monkeys can explain or discuss their work because they simply do not know. It is not due to it being classified or being too complex to explain to lay persons. They are just monkeying around with the keys.
It is important to emphasize that this does NOT mean the Deep Learning has a mind of its own. There is no secret, otherworldly consciousness seeking these - potentially spurious, by the way - generated codes. It is just regression with randomly shuffled biases that either help or hinder its end result (X,Y) accuracy. Each regression layer in Deep Learning does exactly what we tell it to do given a random start. What we tell them is based on the data examples (X,Y). Hence, Deep-Deep Learning (2010s) is like Deep Learning (1980s) is like Learning (1960s). It needs repetitions of reams and reams of clean data.
Clean data means no corruption and no skew. If 2+2=4, we must never ever say 2+2=5. If 2+3=5, make sure we say this only as often as we say 2+2=4. Otherwise, this will irrevocably confuse the Deep Learning. If it occurs, the Deep Learning could easily start outputting that everything equals to 4, especially if that is the most common Y output target. (i.e. accidentally gave juice to the 1000 monkeys after Dr. Suess instead of Shakespeare.) The only way to fix this should it occur: cleanse the targets and start a whole new Deep Learning over again. (i.e. poor monkeys.) Hence, the (X,Y) target data IS the code. The Deep Learning is simply a manifestation of the data. Hence the operators are no longer computer science programmers. They are data science programmers.
This means Deep Learning and Deep-Deep Learning are necessarily true inscrutable black boxes. Machine learning AI in general need not be black boxes - see the 1960s Learning model based on single regression. But they do not seem to work well unless they become black boxes. Scripted AI usually becomes virtual black boxes, but this is due to extremely complex and convoluted, messy code as it expands to new requirements. That is the dirty secret at the heart of AI. In the drive to get the algorithm to work, we sacrificed causal understanding in favor of cleverly accomplishing the stated goal to the letter. You want X to map to Y, we did it. No idea how, but we did it. It's accurate, and it runs fast in O(n) time. But how do we address this dirty secret at the heart of AI?
The answer is to avoid what we term the "Narcissus Trap." The more complex the stated task, the more cleverness to solve it. The more cleverness to solve it, the more we want complex tasks. We pat ourselves on the back because we are truly clever. Except that there are many different ways to state a single implied task. A clever solution to one statement may not address the implied need.
What is AI? Artificial Intelligence. What is Artificial Intelligence? A scripted set of logical rules or a set of (X,Y) target data stored and compressed such that it produces output (Y) in the presence of input (X). This is a perfectly consistent definition, but we are not happy with this dirty secret because this definition is missing something.
What is the implied point of AI? To one day remove the A. What is the implied point of Intelligence? It stores. It processes. It calculates. Yes it does these, but that is not the point.
A working implication of Intelligence is to connect and to grow. Just as DNA helps to grow the species by adapting and connecting to the environment (e.g. grow paws to grip the trees and a tail to balance so we can better exploit tree fruits.) so neural intelligence helps us to grow by adapting and connecting to others (e.g. I gather nuts while you gather fruits. Then we have a big feast together.) Implicit in this connecting is trust (e.g. I would only eat the fruits you collected if you treated it in the same manner I would have.) Therefore, intelligence is not about being canonically correct. It is about mirroring. A recent golfing "Lexi Thompson Rule" puts this in perspective.
Lexi Thompson is a professional golfer. Earlier in 2017, she was on track to win a golf tournament when at the last moment, she suffered a score penalty from actions taken some days prior. Apparently, a TV-viewer played and re-played broadcast video of the tournament with a ruler and a magnifier and discovered that she had illegally misplaced the golf ball. By the canonically accurate and correct rule statement, this violation deserves a score penalty. (X: player moved the ball. Y: score penalty)
However, this penalty itself violated the implied point of the game rules. The point of the golf game is to have fair fun so as to connect players to each other and the game. What constitutes "fair" relies on common sense. Common sense relies on the common connections. It relies on judgment. It relies on executive intelligence. The common executive judgment was that clearly, Lexi Thompson had no intent to cheat or to gain uncommon advantage. The rule was immediately changed to reflect this view. Referees are no longer obligated to act on any additional spectator tips. But they are not obligated to ignore them either. It is up to their judgment. They put themselves in the player's and audience's shoes and decide what best furthers the sport. Then everyone accepts this because it is what they would have done. Now imagine these contrasts between a lay TV-viewer armed with a rule book and an on-site referee executing sound judgment, but apply it to law, or medicine, or banking.
Therefore to change Artificial Intelligence to Accepted Intelligence, we would best be served leaving aside scripted sets of logical rules or stored and compressed examples. Deep learning is not the way. Rather we combine the neuroscience of the what with the management of who we are. There is no perfection in logic or accuracy. There is no cleverness to solve a problem. There is simply growth and connecting.
Combining neuroscience with management is the key. We can attest that neither of these appears in machine learning or AI textbooks. Both emphasize extreme transparency. And neither has ever been out of favor.