
Mathematical neural networks are tactically sound but strategically misguided.
Speech is uniquely special. Noam Chomsky even went as far as to propose a special speech organ with which human babies are born. Children learn to speak idiomatically and accent-wise correct speech in societies where adults provide the language support they need, in societies where adults are apathetic to teaching children to speak, and in societies where adults actively discourage children from learning to speak. It arises naturally even in pidgin forms where children with different languages create their own group "potluck."
(Siegler and Alibali, 2005) Recreating this speech would add an uniquely special understanding of human nature.
Some of the latest work in this application includes Dynamic Memory Networks (DMN), which rely on
long-short term memory networks (LSTM) and
gated recurrent networks (GRU). For this paper, the discussion shall remain at the big picture high level, though further references here can range from slightly lower high level exploration to the original source equations.
The concept is complex enough without the implementation and network diagram
details.
Dynamic Memory Networks use a combination of 4 separate modules to perform question answering - think reading comprehension passage in a standard high school SAT test. The
question module (to find a stated or implied fact) translates the input (a series of sentences)
gradually over several combing passes to form an episodic memory module. This builds up a constructed narrative focused solely on answering the question.
The question module directs the answer module to format an appropriate
response.
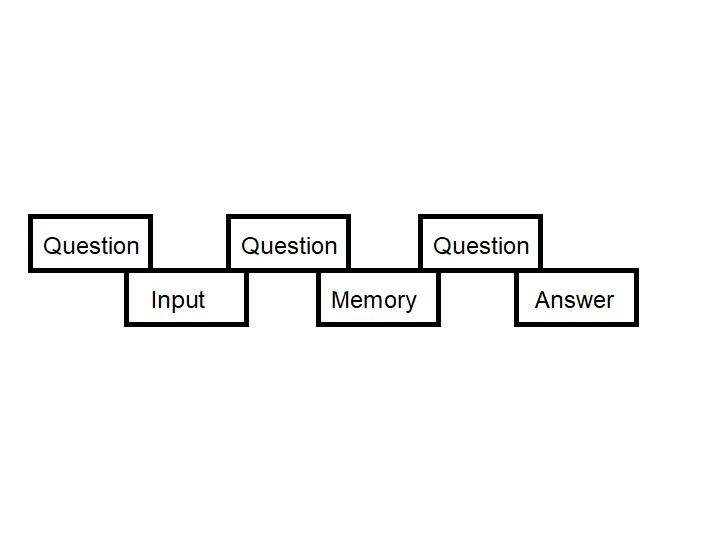
Figure 1: The question module directs and modulates everything.
All 4 modules use a separate mathematical neural network for their operations. In all cases, these take the form of either LSTMs or GRUs. Both LSTMs and GRUs work the same way - they use gates to restrict and control recent inputs' effects on the network so as to retain older inputs (i.e. the nominal longer or shorter term memory in LSTM). They seek to prevent the "out of sight out of mind" syndrome and prevent more recent irrelevant input statements from overwriting older relevant ones. A GRU is an updated variant of an LSTM that fuses some of the correlated gates into a simpler, more compact network. In their whitepaper, the DMN authors term these 1990's-origin gated mathematical networks as inspired by hippocampal episodic memory formation.
Leaving aside "inspirations" - a muse inspires, the dawning sun inspires, a AA battery can reasonably claim to be inspired by brain neurons' chemical ions - the great benefit of mathematical modeling is in translating a concept into separate broken down components that lend themselves to divide-and-conquer solutions. To put the challenge of a reading comprehension speech test in specific terms, here is a illustrative sample input and question(s):
1. Peter visited the shed.
2. Mary visited the attic.
3. Peter got the milk.
4. Mary got the papers.
5. Peter made some butter.
6. Mary audited the records.
Q: Where is the milk?
Right - absolute nonsense with a horrid reading structure. However, it does exaggerate the level of twists and turns into an obvious obstacle course for testing. A Dynamic Memory Net uses LSTMs or GRUs, themselves forms of mathematical neural networks. What would a mathematical neural network make of this task?
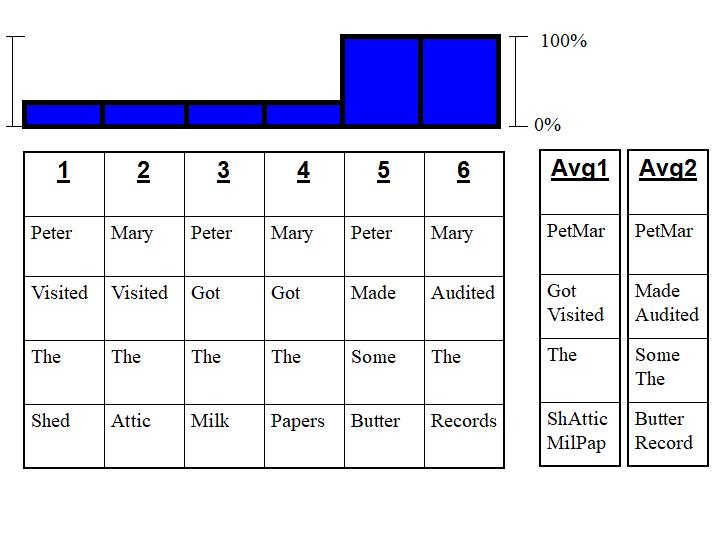
Mathematical neural networks rely on a regression setup with multiple regressors in parallel - one or more per input. It may have multiple layers of these regressors in series - hence the Deep Learning moniker that also describes this type of network. Regression is a fancy mathematical term for summary line average.
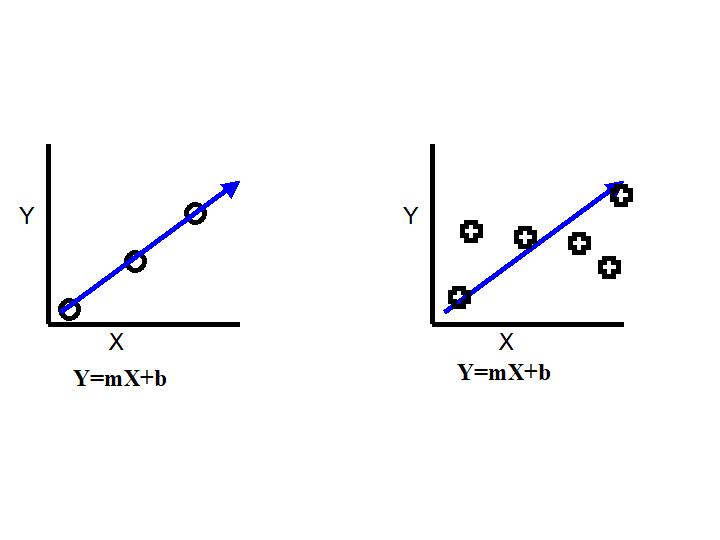
Figure 2: Instead of communicating each and every point, the blue regression
line - think elementary school algebra - summarizes them. Sometimes
well, sometimes poorly.
So a single layer neural network with 4 inputs would average 6 statements into something like this:
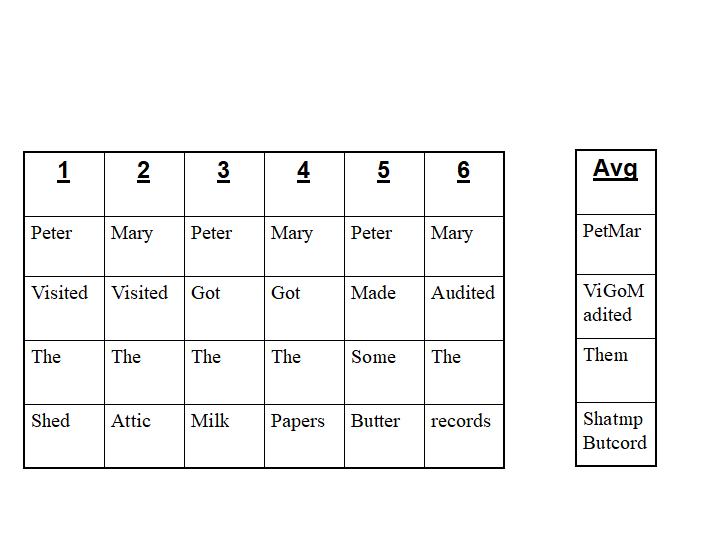
Which would be a stylized average of the 4 input words over 6 different sentences. Since the most common 3rd word was "the," that word comes out relatively clearly. Trying to question extract anything from this train wreck is an exercise in futility. Hence the need for Deeper and Deeper Learning with 40 inputs and many more layers or more specifically, gated and controlled LSTMs and GRUs. The point is that at this early a stage we are already forced to fight against the natural inclination of the
regression based mathematical neural network and patch it up until it suits our purpose.
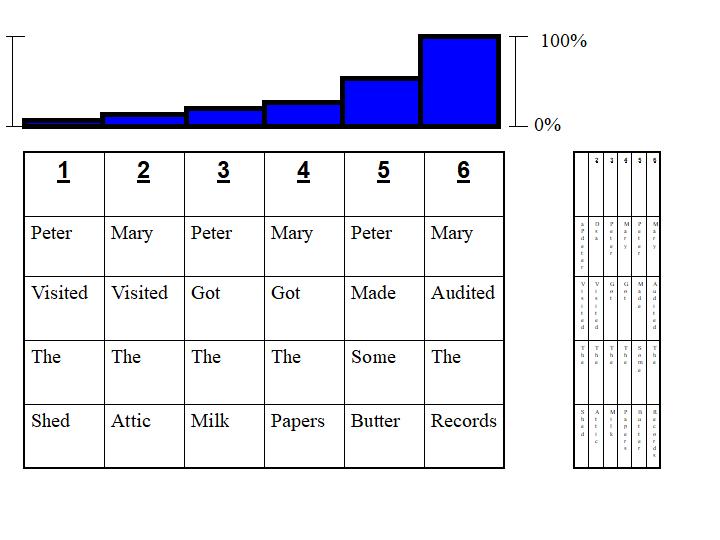
Viewing the 6 statements with a temporal weighting dimension, we would see them like so:
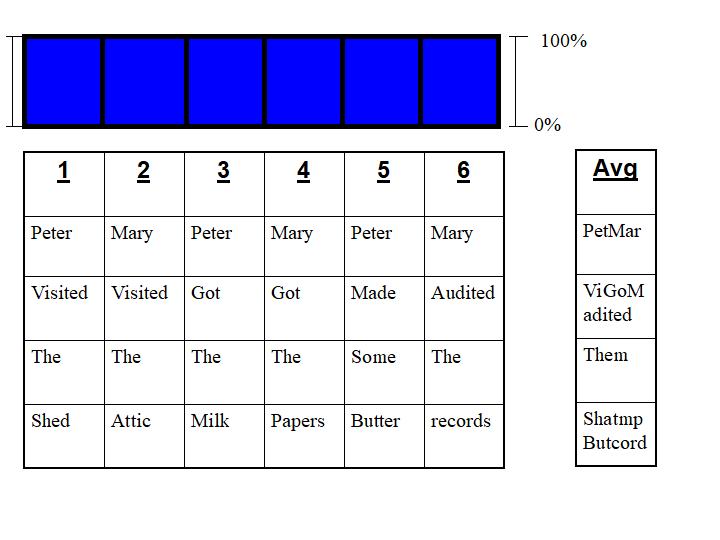
Where again, the basic mathematical neural network attempts to average the 6 statements equally. As with anything in time - physicists would call it entropy - treating distal points as equally influential as proximal ones leaves a great big chaotic mess.
A more complex temporal setup attempts to blend, say, statements 1-4 into one average and statements 5-6 into another separate average. This is the beginning of the separation into "long" (distal) and "short" (proximal) memory. Doing this typically requires a non-linear regression, or local regression. Translation: instead of
Y=mX+b, we need Y=e^(mX)+b. Using mathematical neural network terms and structures, this means we need more input nodes or internal layers or both. Deep learning then refers to a deeper hidden layer - or since these deeper layers literally do not see the light of day via directly controllable observation of input and output, going down a deep rabbit hole.
It is a pity that the discussions from temporal neural networks with DMN, LSTM, GRU, and general deep learning did not typically include input from our colleagues in speech and time signal processing. An exploration of Finite Impulse Response (FIR) filters would be very helpful in this scenario since they have already experienced the pros and cons here. In short, processing a fixed snippet of a time varying signal is very effective - but the downside is that we would need to know in advance what kind of signal it is. The FIR filter design would be too specifically tailored to a particular task - sort of like a "Smart Clapper (1992)" signal detector that detects 2 or 3 claps in a row for 2 different signals on 2 different outlets. But unless the design specifically called for 4 claps, it would not pick out 4 claps.
| "Alexa play Beethoven" | (clap clap) |
| "Alexa play Imagine Dragons" | (clap clap clap) |
| "Alexa why are you playing Imagine Dragons" | (Error e50795 - uncaught exception fault - play voice file: "Sorry I can't help with that") |
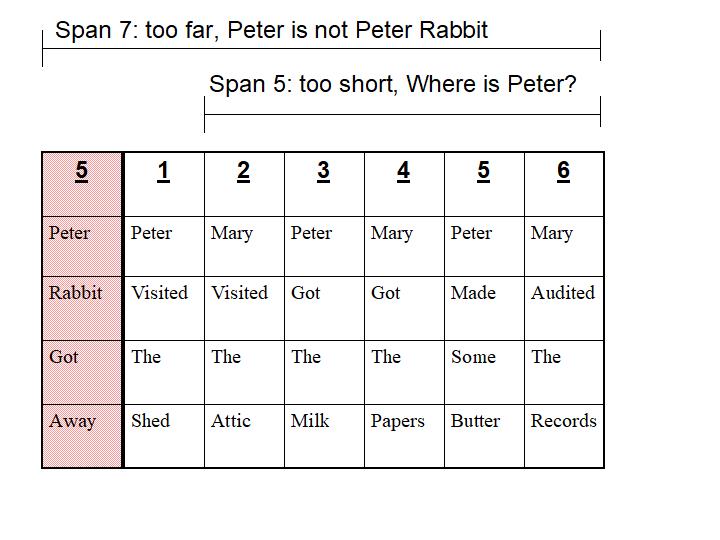
Such a fixed FIR setup would be ineffective on the Peter vs Mary obstacle course here unless the designer knew in advance this particular task with 6 sentences.
A manually set filter for 7 sentences may include irrelevant sentences from
another passage. A manually set filter for 5 sentences would forget
important information too soon.
So the DMN, LSTM, and GRU needed to go the recurrent route. They needed to enter the twilight zone world of feedback.
Feedback theoretically holds information forever, but at low levels so as
not to overwhelm current events. Feedback or output to input recurrence works in regression like this: instead of adding the 6 sentence
functions together independently like this:
f(Peter 1) + f(Mary 2) + f(Peter 3) + f(Mary 4) + f(Peter 5) + f(Mary 6) = average
or keeping 2 separate averages like this:
f(Peter 1) + f(Mary 2) + f(Peter 3) + f(Mary 4) = average 1
f(Peter 5) + f(Mary 6) = average 2
we have this:
f(Peter 1) = remains of Peter 1
f(Mary 2 + remains of Peter 1) = remains of Mary 2 plus recycled remains of
Peter 1
f(Peter 3 + remains of Mary 2 and recycled remains of Peter 1 ) = remains of
Peter 3 plus recycled remains of Mary 2 plus recast recycled remains of
Peter 1.
and so on, where f(x) is a summary or averaging function, also known as a
point compression or location parameter to be fancy. A biological way of looking at a compression or summary is a digestion function. Digestion or recycling expresses the concept in a particularly apt, if unsavory manner.
Needless to say, odd things happen when today's dinner includes yesterday's trash, two days ago's digested trash, three days ago's recycled digested trash, and so on. To put it in numeric terms, we can borrow again from the signal processing folks, this time from an Infinite Impulse Response
(IIR) filter.
Say an input sentence starts off with a 100% signal strength. "Peter visited the shed" Where is Peter? The shed. After f(Peter) is finished, it has a compression ratio of 10%. So after 1 turn, f(Peter) is 10%. After 2 turns, the information about Peter becomes f(f(Peter)) which is 1%. After 5 turns - meaning by the time we have finished processing the 5th sentence, we have the signal strength - i.e. memory signal - for Peter's location at 0.0001%. Theoretically, the memory signal for Peter visiting the shed is still in the system infinitely - hence the term infinite impulse response. But extracting and restoring the infinitely small signal is going to take a 1,000,000% factor (i.e. 1,000,000 x 0.0001 = 100%).
In mathematical neural network jargon, this relates to the vanishing/exploding gradient that exacerbates the stability at local min/max optimization. The network effectively stops learning at a suboptimal, non-universal state. That's a mouthful. While it sounds nicely intimidating, it hardly engenders understanding of the challenge the infinite impulse memory presents.
To put it in a computational neuroscience-y perspective, there is a fun climactic scene in the Pixar movie Ratatouille
(2007) where the secondary antagonist - a food critic - challenges the chef to "surprise me" in showing the chef's best dish. The chef makes a simple
ratatouille. With a single bite, the food critic recalls a flashbulb memory of being comforted by his Maman's ratatouille after a rough day as a child. He is astounded that such a boldly simple choice can be such a wonderfully, brilliantly evocative meal transcending the mere caloric and gustatory. The ratatouille was not simply a dish as it was a vehicle for transporting back in time.
In an infinite inpulse response feedback setup, the critic's childhood memory might be 50 years ago. The expansion factor to bring the distant memory back to the present 100% level - needed to compete vs. present inputs - would require
a one and perhaps more zeroes than there are atoms in the universe. Instead of bringing a distant memory back to 100% with a single bite of ratatouille, the chef would need to smack the critic upside the head with ratatouille. For 50 years. Clearly this did not happen. Nor would we expect to need this to happen. So one could reason a long term memory would somehow not decay in a feedback operation to an infinitesimally small compressed value. How?
A DMN uses LSTM or GRU modules to attempt to store a sentence by freezing them. These modules use gates to override their normal network operations - again, this add-on "band-aid patch" that fights against the network's natural inclination and purpose of constant adaptation and change. These gates maintain, say "Peter visited the shed," in a pristine - say cryogenically frozen state. So far so good. Obviously not an ideal solution since we begin to approach Rube-Goldberg-ian levels of patches and fixes and overrides, but it should work after all that effort.
But there is one glaring flaw. This approach does not actually store a memory. (Learning and memory happen to be one of this author's neuroscience and business specialties.) Rather, this approach solves a particular problem of answering a question. To split hairs, one may call the DMN framework using LSTM, GRU, and deep learning as "question-centric answering memory" (QCAM) but having little to do with episodic or semantic or procedural memories - themselves broad approximations and placeholders.
See figure 1. Note that the whole frame work is dependent on the question. Based on the question, the DMN combs through the input passage multiple times until it converges on a formatted answer. The problem in layman's terms: the
example food critic could only freeze-store his childhood memory of Maman's ratatouille
as a child if and only if he knew as a child that he would be eating ratatouille 50 years in the
future in a chef challenge. Based on the team's own technical report, the approach is unsuited for long input passages or for multiple questions.
The real reason is not simply an issue of processing speed that can be fixed by Moore's Law. The reason is
that the flow of time (physicists would call it entropy) is only one directional for all intents and purposes.
How does one decide what they need to remember before being asked what they
need to remember?
A mathematical neural network - which forms the basis for DMN, LSTM, GRU, and deep learning - derives from a McCulloch and
Pitts (1943) neuron model showing how a motor neuron (mechanically observable) might work. All the enhancements of latter years are a direct response to getting that model to work in different scenarios ranging from X-OR
(exclusive OR boolean logic - see Rosenblatt, 1957 and Minksy and Papert,
1969) to answering a question. But the reason recreating human speech would add an uniquely special understanding of human nature is not about answering questions. It is not about reforming the input into a QCAM. It is about demonstrating our - for lack of a better word - free will in deciding what to say in response. In deciding what to remember.
An adaptive resonance theory approach (1973) for example is an abstraction not of
a mathematical neuron, but of a psychological memory. It does not seek to demonstrate a constantly adapting neuron, nor a regression summary, nor a gated patch. Latter interpretations rely on endocrine reward expectation and anomalous surprises to create or assign new
independent cells. Where memories are not specifically input sentences or question-centric input sentences, but rather whatever the owner found interesting such that the body's endocrine system pumped him full of dopamine drug highs. A memory is extremely personal. Because its very existence is alone a testament to the owner's feelings, hopes, and dreams. And narcotic drug highs.
By itself, in absence of any question, such an approach would organize the inputs thusly:
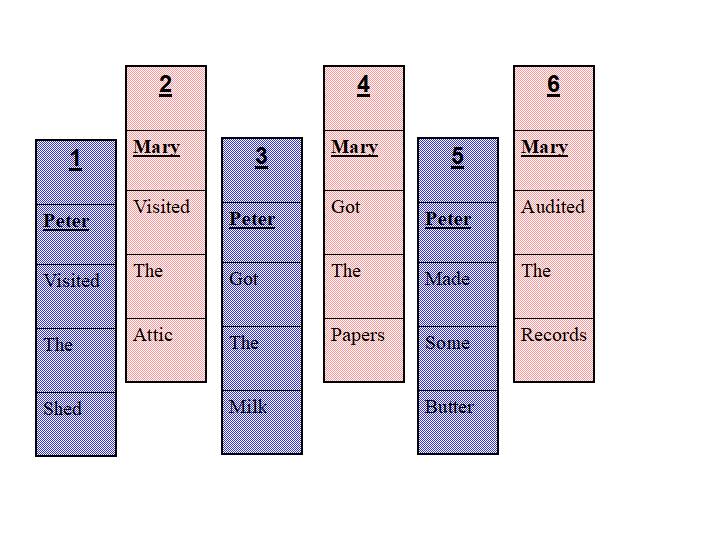
There are clearly 2 separate passages, one centered on Peter and one
centered on Mary. Having this clue alone obviates the need for much of
the patchwork modules for freezing and gating memories. How does one
keep these two interleaved story averages from overwriting each other?
Don't try to average them in the first place.
Peter and Mary would be particularly salient due to a lifetime indoctrination on emphasizing genders,
sex orientation, and visual images associated with Peter and Mary. However, the results here would be unchanged even without such history. Peter's activities naturally separate from Mary's because of the commonality of "Peter" with "Peter" and nobody else. There is no conflict or overwriting and therefore no need for de-confliction and overriding. And there is no explicitly added controlled gate patch in sight. The primary obstacle of the twisting and turning input passage requiring decades of hard work to work around is no obstacle at all - given a different basic approach.