
If my dog eats my homework, can my AI ChatBot feed the dog?
A question that often comes up to us is how modern artificial intelligence and machine learning transforms the learning and management experience. The latest question involved a university department head's concerns on their PhD candidates cheating using ChatGPT-like tools. Using a few well placed prompts, might not a student create a dissertation with the push of a button? Since the generated document does not trigger phrase matches with existing documents, anti-plagiarism filters could not catch this form of academic dishonesty.
Let that one sit for a moment. The question is in reality, "can it be that our technology is at a level that a large language learning model can plausibly pass as a doctorate, the highest rank of learning?" That would be clearly the case of "welcoming our computer overlords" as Ken Jennings once said. If we cannot distinguish a doctorate who explores the unknown and pushes the boundaries of knowledge from an Alexa app, then only pure stubbornness and Philistine tendencies would hold us back from embracing new leadership.
Now we step in. What are we dealing with here? Here is a report on how AI can solve math equations at any given level, plus commentary on how teaching can adapt. Their discussion and suggestions indicate a "submission" to the inevitable merging with technology and how teaching methods must shift to incorporate AI in tests and homework.
i.e.
- They are new
- they work
- they are here to stay as there is no stopping them
Lest we harken back to the dawn of modern AI and point out that mathematical proofs were already among the first targeted use cases to demonstrate intelligence, note that the math problems in recent cases were math word problems - among the most difficult of tasks because it involves extracting the necessary points to place into the equation the first place. Another example of the modern AI tool in question demonstrates its writing generation. In this second case that dives just a little deeper but in fundamentally the same problem, the AI tool could generate a "ventriloquist" response as if from a different writer; in this case, a 4th grader. So not only would the AI rule as overlord, but it can rule with the voice and tone of an 8-year-old.
There are even recent reports on how some of these AI tools replicate brain science (Kim, et al., under review) in how they operate. This hopefully puts paid on the debate on whether AI is an analogous, divergent mechanism that differs from intelligence or is a homologous, shared-root mechanism that potentially replaces intelligence as we know it.
To expand this aspect just a little further, analogous approaches to a given function derive from different origins. They bear little resemblance to each other outside of any intersection point, which means they fundamentally operate in different manners and thus cannot replicate each other outside of their intersection. In the movie Jurassic Park (1993) a dinosaur could potentially figure out how to open a door. This only indicates the dinosaur could be clever at that intersection with human tools; it does not imply the dinosaur will continue to be a scientist and invent rocket ships. The one cannot recreate and replace the other as they fundamentally do different tasks. Mathematically speaking, one is not a proper subset of the other.
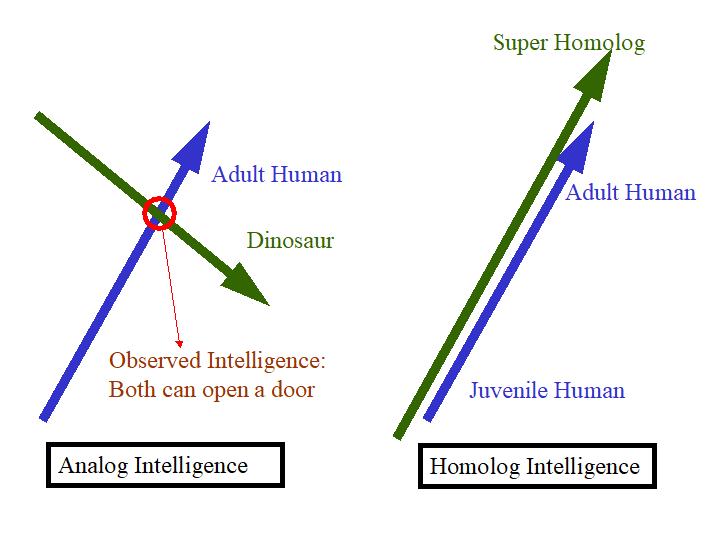
In contrast, a homologous approach derives from similar origins and replicates the same processes and procedures. Homologs can and often do replace each other as they evolutionarily compete in the same exact space. Mathematically speaking, these are proper subsets. The claim being advanced by the above-mentioned report and increasingly in the general discourse is that programs like ChatGPT and others using neural network-inspired algorithms are homologous approaches.
- and it is us
If it sounds like a magic trick and too good to be true, then let us look for the trick. We need to dive behind the scenes - just a little - to discover what exactly is going on. Now a disclaimer: a magic trick is not cheating or fraud. Unless of course they are asking for massive investments based on a conspiracy, here defined as attempting to exploit an information asymmetry to cause material loss. i.e. They know something, they don't want us to know it, and their ability to demand money depends on keeping it that way. Anything else is not cheating, including the designers not even knowing what it is they have done. Then it is truly a magic trick: useful, amazing, and a good learning experience on how and why we perceive magic tricks. It might still be a good investment, but we acknowledge the unknowns and risks and price it accordingly.
The American folk hero story, John Henry, first sets the stage by revealing some of the earlier magic tricks of man vs machine (nps.gov). In this story, John Henry with his muscles and two hammers duelled and outperformed a steam-powered machine hammer. Though John Henry would subsequently die from exhaustion. So today we use machine hammers, only they are now gasoline-powered.

Image of John Henry statue from National Park Service
Artificial muscle (AM): not new, but it works, it is here to stay, and it is not us because it is an apparent divergent analog that does not directly compete with fundamental intelligence. That is point A. Drop a pin here because we will come back to this point about machines, muscles, and intelligence.
But the point for now is that while AM on first glance technically wins by surviving vs John Henry in the long run, winning has not changed anything more than inventing a hammer changed John Henry. We could imagine a Bob Henry using his fists to hammer rocks competing and losing out to Jim Henry using a bronze hammer, who in turn eventually lost to John Henry who had two steel hammers. Perhaps the Henry family just knows their rocks, irrespective of the hammering tools. John Henry is not a hammer. John Henry breaks rocks using the best tool that suits the job. If he were more patient, it would have been John Henry wielding two steam-powered machine hammers.
Moving forward to today, a similar but unconquered machine challenge might be dishwashing (nrn.com/technology). Taking a baby step to practical learning and management in the face of machine learning, furthermore imagine we run a school for dishwashing personnel. One of the students' tasks is to wash dishes. We set the key performance indicators (KPI) on their final exam on quantity washed, quality of wash, and breakage rate. Our classical instruction covers how to pre-scrub, soap, rinse, handle, and stack the dishes. The graduating class handles themselves with grace, class, confidence, and the ability to step in and do the dishes.

Image from Nala Robotics, as posted on Nation's Restaurant News.
Then enterprising little student Jimmy gets his hands on a Maytag dishwashing machine. Maybe it's a fancy one with all sorts of bells and whistles and can handle not just unstained plates but also bowls, wineglasses, pots, and pans. It is so advanced that it scans in dirty dishes, destroys them, then 3D prints brand new replicas. It's the Maytag GPW-9000: the Generative PreFab-Washer, version 9000. Now the dishwashing school department head can't tell if Jimmy's plates are really, really clean or just clean fabricated. Jimmy gets extra points because for every 100 dishes, he not only washes 100 perfect dishes, he apparently washes 105.
Is Jimmy cheating? Or should we update the curricula and KPI to accommodate new technologies like the Maytag GPW-9000?
Or are these the wrong questions to ask, the asking of which constrains and traps us into not seeing the magic trick? Rule #3-4 in couples, communication, and management therapy: if the argument makes no sense, then it is not the real argument. Do not rely on the other party to explain what they really mean because they might not be able to themselves.
In the sample fictional dishwashing school, the students practice by performing on KPIs, but that is not what they are really learning. They and their teachers may not even realize it, but what they really learn at dishwashing school is the ability to handle their cohorts with grace, class, confidence, and the ability to step in and do the heavy work. They are really learning about working in a team. They demonstrate trustworthiness by happily handling fragile yet potentially heavy, dangerous-if-mishandled, and grimy objects upon which the team trusts their food. After graduation, everyday they do dishes, they are actually interviewing for advancement to another job: head dishwasher, chef, gardener, child care, accounts manager, chauffeur, client relations, all of which require trust, grace, and confidence on fragile and potentially grimy or dangerous-if-mishandled objects. In this case, while Jimmy's Maytag GPW-9000 is chugging away, if Jimmy is not elsewhere gaining the experience in handling fragile yet potentially heavy, dangerous-if-mishandled, and grimy objects upon which the team trusts their food, then Jimmy is definitely cheating himself of the training as surely as Olympic marathon runners would be cheating themselves if they trained by riding motorcycles. And if Jimmy is elsewhere getting the same experience, then why is Jimmy not in that school instead?
Now apply these concepts to text writing. Outsourced document generation is likely as old as time. We have professional writers to do our homework for us - homework that includes telling stories to our children. We call them children's authors. They write us children's stories that we read to our children at bedtime. We (hopefully) read them first, or at least the editor read them for suitability for small children. We select them and evaluate them and pass the story to our children. They are not our exact words per se. It is no secret, since the author's name is on the book. But they are ours still because we selected and chose them. We approved them. But that is not cheating because (A) we are not conspiring to defraud the audience causing any material loss and (B) the ability to craft bedtime children's stories is not a core competency in childcare. The ability to spend time and select a suitable story to read out loud is.
The example above of the AI generator creating a 4th grade style essay is an amazing magic trick. The trick is buried right in the text - the expert searched for, selected, and procured a set of 3 additional target essays. With a very user friendly text prompt-based user interface (UI), the expert could generate and re-generate similar documents - a close mathematical explanation would be selecting custom stratified averages of sample documents - until they approve results close to what they had in mind. It is a trick that parallels and complements what visual artists might do with a suite of image filters and generators to touch up or modify and enhance one or more existing images into a stylish blended creation. The intelligence behind the tool, such as it exists, exists in the decision to search, select, and procure the material samples and to evaluate the generated text. Everything else - from system prompts to database internet search to hidden latent layer simulated annealing generation operations - serves as an enhanced and easier-to-use UI (user interface). Any such intelligence exhibited through this process is in actuality a mirror reflection of the user's own intelligence.
But is that cheating? That is an entrapment type question because we cannot answer cheating or not cheating by degrees - is this 50% cheating? Is that 10% cheating on the cheating-or-not-cheating axis? Rather we need to go back to our definition of cheating and fraud: is it attempting to exploit information asymmetry to cause a material loss? Buying a children's storybook is not cheating. Creating a 4th grade style essay is not cheating - whether by using crayons or Adobe image processing or an AI text generator from a summary of multiple source essays - if it is for use in a children's storybook.
The act or usage thereof does not define cheating. But in a school for giving students experience in collecting ideas and framing thoughts to practice communication styles for different target audiences, then secretly using an AI text generator like ChatGPT constitutes cheating since (A) it exploits information asymmetry by attempting to obscure the text origins and (B) the student is cheating himself of provided services on a stated or implied goal of the school for which they directly or indirectly paid. The school collects fees to provide simulator training in a safe environment. The student is cheating himself by not receiving that training if they secretly avoid such training.
Conversely, if the school provides training on how to operate the AI ChatGPT like tools and a student secretly produces their own writing and passes it off as an AI creation thereby secretly skipping on receiving the practice experience in operating said system, that is cheating. The difference on which end of this cheating-vs-cheating axis we prefer depends on what we desire in our employees. In one case, we hire employees who need an extra week of worktime to start operating a tool, but has the practice in creating new ones as the business environment shifts. In the other case, we hire employees who can start operating the tool immediately, but we need to let them go and hire new employees if the business environment shifts. And we would never get any business advantage from creating our own competitive edge.
To explicitly answer the concern about generated PhD dissertations: the dissertation itself is not a mark of the doctorate. Technically, the dissertation is simply the form paperwork bow-on-top to decorate the student's work and hands-on evaluated training. The skills required for a doctorate include the ability to independently pursue the bounds of the unknown, which by definition means alone, underfunded, unbelieved, and with no precedent from which to start, only to have to continually defend and proselytize even after finding hard evidence. Fundamentally, a well written dissertation is not even a requirement. So a ChatGPT cannot help a doctorate to cheat to pass as a doctorate with a generated dissertation since the dissertation in itself is meaningless.
To update the bullet points thus far:
- They are not really new
- they work by simplifying one or more specific use cases
- they are here to stay as there is no reason to stop it. It is a nice tool that extends existing tools.
And finally, are they us? Is modern AI of the ChatGPT-type a homologous, similar mechanism that potentially replaces intelligence as we know it? Is it worth investing in beyond as a user friendly search and summary tool but also as a model for researching, designing, and emulating intelligence homologues?
Some brief definitions are in order.
First, Intelligence (I) refers to the qualia of human intelligence, colloquially a trait that all humans possess (barring certain cases of extreme brain damage or vegetative states) but no other entity possesses. The classical routes of study on intelligence include psychology (behavioral models), neuroscience (neural model dynamics), and economics (rationally constrained group intelligence at equilibrium).
Second, Artificial Intelligence (AI) refers to any overlap of behavior between that which can be manifest in a computational algorithm and that which can be observed originating from a human. Alan Turing's work included thinking about how an algorithm could possibly produce such behavior and how to recognize when or if it did. The widely known Turing Test is an early such attempt at a recursive definition. In mathematics as in language dictionaries, relying on recursion as a definition is a sure sign of essentially "tossing in the towel" and should be treated as such. This is a hard topic to define.
Thirdly, Artificial General Intelligence (AGI) refers to a subset of AI research focused on addressing the fact that AI research progress has been sporadic, piece-meal, and restricted to clearly defined goals and use cases. AGI attempts to demonstrate multiple use cases in one single system without prior need for significant redesign. To put this in perspective, imagine Jimmy's Maytag GPW-19000 that can wash dishes AND laundry all while reducing the need to swap dishwashing detergent for laundry detergent. Doing them both at the same time is an optional enhancement. This is a relatively novel term with vague boundaries (Wired.com).
The study by Kim, et al. (under review) referenced above is one of a relatively few multi-disciplinary studies combining neuroscience and computing. It serves as a great starting point for discussing our current high-level status on where we are on the "are they us?" bullet point question. At the risk of boiling down to simplicity, the key terms that describe the findings and are thus the key terms after which we define can give us at least smart-sounding discussions are:
Hippocampus: translated from "sea-horse-like" shaped region located in the temporal lobe, it is one of the first parts of the brain destroyed by Alzheimer's Disease (pubmed). Henry Molaison ("Patient H.M.") lived with temporal lobectomy causing a mostly removed hippocampus, but was otherwise unaffected by Alzheimer's Disease. Both types of cases are characterized by having impaired ability to store long term memories. One could literally serve them chicken soup for lunch and 5 minutes later they have no memory of what they just ate. Therefore, the hippocampus must be a central gateway for storing long term memories.
Transformer: Of which the GPT-x series is an example. A form of neural network built especially for sequences like text, but dispenses with time ordered sequence information to speed up the storage (e.g. "encoding") process. The storage process, crude-analogy notwithstanding, finds links between all words and phrases in a mass of text, very much as if massively linking all parts of all the internet webpages. The generation process ("decoding") creates a sequence of words one by one, each based on both its found ("encoded") links and what it just generated. Again, crude-analogy notwithstanding, it generates as if it automatically opens a sequence of webpages (or zoomed in on relevant parts of webpages) for the reader, replicating the link-click-scroll browsing experience without the reader actually needing to link or click or scroll.
NMDA: acronym for N-methyl-D-aspartate. A little background: each neuron contains neurotransmitter chemical messengers. When a given neuron receives enough stimulation, physically represented by calcium ions crossing the neuron membrane, it triggers the neuron to release neurotransmitters in a one-way directional blast to neighboring neurons. Glutamate is a common excitatory neurotransmitter. Think of glutamate as broadcasting an exciting action movie on the glutamate streaming channel. Any neighboring cells tuned in to the glutamate streaming channel receives the show and become excited accordingly. Think of NMDA Receptors (NMDAR) as being a glutamate streaming channel app.
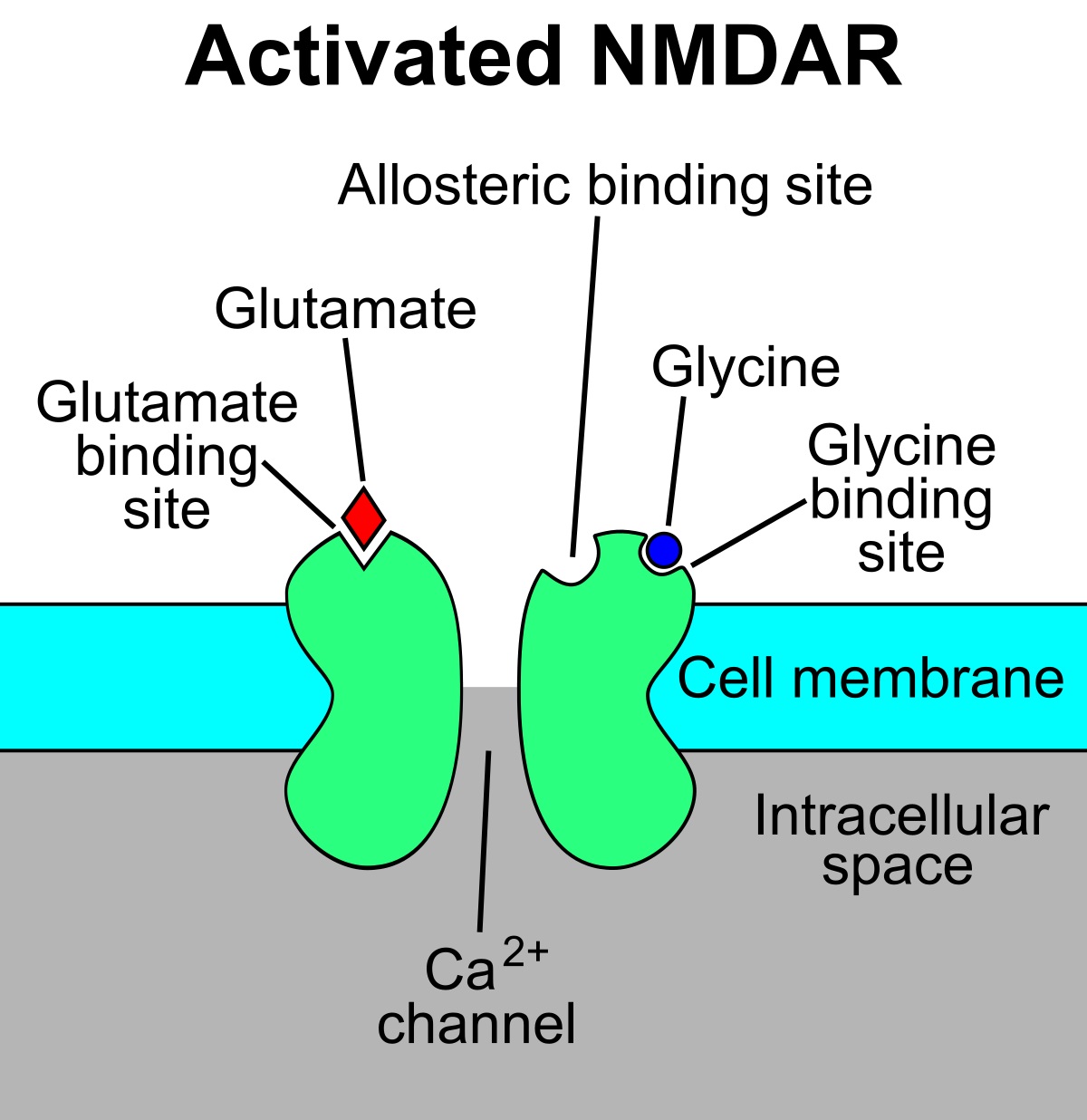
Simple Wikipedia image roughly showing position of NMDA receptor.
If the NMDAR-equipped receiving cell in turn becomes sufficiently excited (i.e. hosts a successful action movie party), it adjusts its NMDAR receiver to better detect the original broadcasts. In modern day social media terms, the NMDAR-equipped neuron "friends" or "subscribes to" the broadcasting neuron from whom it received the broadcast. This describes Long Term Potentiation (Cell.com/neuron).
NMDA receptors are also severely disrupted (National Library of Medicine, nih.gov) during Alzheimer's Disease. Clearly, the above 3 terms are related to each other as they all refer to memory storage functions. Then again, the overall main purpose of a computational neuroscience neural network is literally to explore different structures to store and retrieve memories. Adopting one or more concepts from a neuroscience model for commercial computing products is bound to inherit some element of biological plausibility.
On the other hand, the models from which transformers inherit their operations only dealt with information storage and not a theory of intelligence itself. No surprise there as that is typically beyond the scope of most neural network models. To say that a commercial product based on a model of abstracted, stylized representation of partial ion flows represents intelligence in any meaningful manner is akin to the premise that commercial AA batteries are living because they also deal with gated ion flows across positive and negative battery cells. Especially given that with that particular source neural network, the focus was on data storage into stochastically compartmentalized latent layer spaces.

Translation: think of the video game Tetris, where the operator fits each data chunk into a particular location to make the most of the space for other data chunks. That is not too far from that neural network's goal. Now imagine that the primary strength of the transformer lies in its ability to pack many, many such chunks very rapidly. The signature blended recall of multiple chunks - the decoder or generator - harkens to neural crosstalk, the network condition where multiple different stored data chunks recall each other. But if this were a credit score environment, then we just retrieved John Doe's, John Smith's, and Jim Do's credit histories when we wanted John Doe's credit score. That is not intelligence in any way. But it is very automated and consolidated link-click-scroll browsing search.
To summarize,
- AGI is a subset of AI
- finding the intelligence in AI is a circular search since there is no actionable definition of intelligence
- a neural network based product inherits base properties (technically a homologue or same root)
- but those properties were not of intelligence, so therefore not related to intelligence
Actually, in the case of transformers inheriting from neural models, that neural model in question in turn focused on inheriting storage models from computing. Technically, we have on hand a computer transformer model which emulated a network model that emulated a computer. More circularity, and the circularity of a computer chasing a computer is deliciously ironic.
- and it is not us, but itself.
A transformer is neither homologous (same root) nor analogous (different root but convergent function) to intelligence but homologous to a transformer computer function. It may be a great product and a great useful tool, but only inasmuch as a massive, easy to use library card catalog serves to aid and connect research. It no more fundamentally changes the learning and management experience as regards to cheating or replacement with overlords as did the written word, libraries, or internet. Further reading on a similar perspective here at MIT's Technology Review.
- Updated, 2024 to expand on the definitions and applications of analog vs homolog.