
What do neural nets actually model?
Everyone knows neural nets simulate brain-based intelligence. First elucidated in component form in 1943 (McCulloch-Pitts Neuron), and later extended to network form by the 1980’s (Perceptron, Multilayer Perceptron), neural nets had even entered popular culture by the early 1990’s. For example, Arnold Schwarzenegger’s character in the Terminator franchise as early as 1991 claims his terminator machine brain is “…a neural net processor; a learning computer…” The belief is that neural nets provide a quantum leap in artificial intelligence. In keeping with this trend, ratings agencies, lenders, hedge funds, military departments, and others began attempting in the 1990’s to use neural nets to augment human analyst intelligence in their respective tasks of identifying default risks, timing equities trades, and highlighting satellite images of interest. And if some company decides to build terminators, a natural first attempt will incorporate neural nets.
But for all the sound and the fury behind neural nets, we might now ask what exactly do they represent? If we can build neural nets that can simulate and replicate human intelligence, then we must by definition know how exactly what is human intelligence and how it works. Good engineering and design does not come from blind, hopeful submissions and counting on chance to cover deficiencies in knowledge and experience. With that in mind, here are some basic beginner facts about the brain and intelligence as scientists know them.

The skull completely encompasses, protects, and constrains the brain.
The adult human brain composes about 3% of the body mass and
consumes about 25% of the body’s calories.
There are approximately 100 billion neurons and 500 trillion
synapses. Human brains grow
very quickly starting in the womb, leading to potential complications in
child birthing above and beyond what any other animal ever experiences.
The brains then slowly lose cells over time.
Humans are the only known species to walk predominantly upright on
two legs, also leading to the birthing complications.
If evolution is accurate, this implies the above two facts are
important for human intelligence since these costs are apparently worth
it.
At the micro scale, neurons are the primary cell actors in the brain and nervous system. Each neuron contains dendrite receptors attached to the cell body, each ready to sense and receive chemical transmitters from other neurons. If the dendrites and cell body receive enough transmitters in a given time frame, the cell body transmits its own signal down its tail-like axon to project chemical transmitters to its particular target neurons’ dendrites. Since neurons use chemical transmitters rather than electron or light pulses, maximum neuron transmission speed is less than 100 meters per second. Afferent, or inbound neurons to the brain connect to all senses – eyes, ears, skin, nose, and tongue. Efferent, or outbound neurons from the brain send signals to the rest of the body. Inter neurons begin and end within the brain without contacting any sensory organ. The ratio of afferent to efferent to inter neuron is 1:10:200,000. If physics is accurate, the above two facts are important since chemical transmission is very slow yet directional compared to electrical transmission.
At the macro scale, brains are segmented into fairly consistent specialized regions, first marked by Brodmann in 1909. Vision, speech, somatosensory, olfactory and other functions are correlated with precise brain lobes and regions. Knowledge of brain anatomy rapidly advanced in tune with advances in medicine and head protection in the 20th century that allowed soldiers to survive head trauma and patients to survive brain surgery. Correlating patterns of brain disabilities with patterns of mental disabilities yielded a brain function map. Losing the medial temporal lobes and hippocampus, for example, leads to loss of episodic memory and anterograde amnesia even though procedural memory remains intact. To add to the complexity, brain injury or surgery occurring at an early age leads to milder mental disability. If these injuries are accurate, how the brain reacts to damage occurring at different stages of life provides important clues on how the brain develops and leads to intelligent behavior.
At the meta scale, development in the brain may be dependent on development in the peripheral nervous system and environment. Cats, for example, only develop vision in an eye if neither or both are operational during their early years (Hubel and Weisel); covering one eye while leaving the other operational leads to permanent blindness in the covered eye. In addition, cats only develop depth perception if they are free to self-locomote. While there are no known controlled, ethical studies on human sensory or cognitive development in the same manner as cats, observational studies have yielded similar interpretations of environmental impacts on intelligence. For example, English speaking children tend to identify objects as similar by shape (e.g. cardboard box with plastic box) while Yucatec Mayan speaking children tend to identify objects as similar by material e.g. (cardboard box with cardboard sheet; Lucy, 1992; Lucy & Gaskins, 2001). The Guguu Yimithirr Aboriginal language emphasizes absolute spatial orientations (e.g. object A is east of object B) while the Dutch and English languages emphasize speaker/listener spatial orientations (object A is left of object B; Levinson, 1997). If these observations are accurate, how the extant culture and environment affects brain and behavioral growth provides important clues on the mechanisms and definitions of intelligence.
When research, business, and media refer to neural nets, they typically refer to the quintessential multilayer perceptron (MLP) and variants thereof. Multilayer perceptrons consist of multiple perceptrons arranged in layers, roughly analogous to how neurons connect in the brain. Each perceptron in a given layer receives inputs from all perceptrons in the preceding layer, processes these inputs using a sigmoidal transfer function simulating how a neuron processes neurotransmitter reception at the dendrites, and generates a weighted output value towards all perceptrons in the following layer. This output generation is weighted to simulate the axon terminal’s synaptic proximity to its target neurons; proximal target neurons receive a multiple of the output generated while distant target neurons receive a fraction. If the ultimate output response from the final layer is incorrect, the MLP generates an error correction signal that adjusts these output weights. The weight adjustment simulates how an axon grows towards or away from its target neurons. (See here for a short walkthrough of the MLP procedure). Mathematically, given sufficient perceptrons, layers, and time, an MLP-like model can theoretically approximate any known or unknown equation automatically (Hornik, et al., 1989).
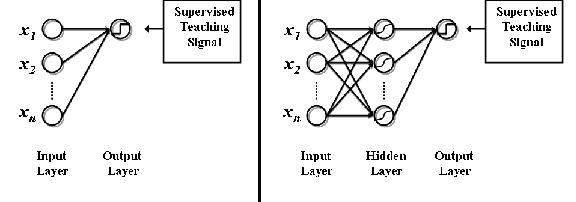
Leaving aside for a moment the micro scale biological neuron modeling via perceptrons, if this MLP basic concept appears intuitively familiar to a regression model, that is because they are related. In the figure above, the left side represents a standard multiple regression. The x variables comprising the input layer are the independent variables in the regression equation. The output layer variable(s) are the dependent variables. The basic translation of the left diagram into equation form would be:
![]()
The a-values are the weights of each x-variable dictating their individual influence on the final y-output. Regression works by finding and fitting the optimal a-values to generate the correct y-output. An MLP, represented on the right in the above figure, simply extends the regression equation with hidden layers. These hidden layers allow the MLP to recombine subsets of the x-variables to reveal novel, complex relations. For example, regression on the left side of the figure only allows variable x1 to directly independently affect the y-output. An MLP on the right side of the figure allows variable x1 to work indirectly and dependently with variable x2 and others to combine into a latent hidden layer variable, which then affects the y-output.
MLPs can be extremely complex models incorporating many different classic machine learning concepts into one entity. It is no wonder they were popular in the 1990’s – and still are, making nearly half of all financial research and business papers dealing with neural net applications since 2000 (Wong, 2011). However, everyone knows neural nets simulate brain-based intelligence. They are not supposed to model machine learning based intelligence. How well do basic MLPs as proxy for neural nets measure on the biological plausibility and micro, macro, and meta scales as detailed above?
Theoretically, an MLP can incorporate 100 billion perceptrons (neurons) with 500 trillion weights (synapses). However, there are very few variants that allow the MLP to grow (Fahlman & Lebiere, 1990) and fewer still that constrain the MLP size or allow the MLP to lose cells and shrink. MLP setups tend towards static, predefined structures tailor made for a specific task. While MLPs can theoretically connect to stand-ins for afferent sensory and efferent motor and feedback connections, typical MLP structures do not come close to the 1:10:200,000 ratio of afferent to efferent to inter (hidden) neurons (Kaastra & Boyd, 1996). In fact, MLPs in research and applications tend to have far more afferent (input feature or x-variables) than efferent (y-output) nodes.
At the macro scale, MLPs in any form do not specify which brain region they seek to simulate. They are completely unsuitable theoretically or empirically to simulate hippocampal regions of episodic memory, for instance. Due to an MLP’s incremental error correcting and learning nature, a brain modeled entirely by an MLP would need to watch the movie Terminator thousands of times before being able to recall anything meaningful about it. Also, corrupting or damaging the MLP structure has no different impact on current retention and future learning capabilities depending on when in its development the damage occured. Except on a superficial level, MLPs do not simulate brains on the macro scale.
At the meta scale, there is no specific treatment in research or business publications on how the external environment or culture affects an MLP. The majority of research papers focus almost exclusively on internal neural net structure and error correction rules. While MLPs are supervised learning systems and dependent on the input data and ground truth labels, there are typically no provisions regarding the input data and ground truth before it gets mechanically fed into the MLP. If assumptions regarding the input data and ground truth are incorrect, then no amount of complex internal learning and transformation functions can properly reflect brain-based intelligence. While this neglect of external factors is hardly unique to MLPs, it still contributes strongly towards its divergence from brain based intelligence modeling.
The final tally, out of four general points at the very basic level? Biologically, neural nets as defined by MLPs get half a point since they superficially resemble brain functions. On the micro scale, they get half a point because they can theoretically mirror the nervous system though that day has yet to come. On the macro and meta scales they get zero points. The total is one out of four.
In 1969, Minsky and Papert published a mathematical analysis of neural nets that expressed doubt about their capabilities. Many researchers believe this single book was responsible for the dearth of neural net research in the 1970’s until the development of MLPs in the 1980’s revived interest in neural nets. It is definitely controversial and possibly maligned, yet it served an important function – it forced the question as to whether neural nets, as defined by the MLP and its derivatives, can properly simulate brain-based intelligence. Neural nets are in use today. IBM’s Watson uses them. Google uses them. Banks and credit agencies use them. But the question is not whether they work or help in performing analysis – a fancy enough regression or a combination of machine learning tools could do the same. The question is can a neural net ever attain brain-based, human-like intelligence?
The short consensus answer today is: not yet. The public explanation why points the finger at the hardware. If only the hardware can be fast enough, the belief goes, then one day there shall be real androids with true brain-based human-like intelligence. But in private, we must wonder whether we truly understand what is brain-based human-like intelligence. One point out of four is not a passing grade.